Eine Datenbank ist eine Sammlung von Daten eines bestimmten Themas oder Bereiches, die so
abgespeichert sind, dass Auswertungen und Suchen relativ einfach sind.
Datenbankmanagementsystem (DBMS)
Ein DBMS ist das System um die Daten, das Funktionalitäten bereitstellt, wie z.B. SQL als
Schnittstelle, Verwaltung der Daten in einer Struktur, Sicherheitsmechanismen für Zugriffe,
Transaktionshandling, Sicherungs- und Recoverytools, Optimierungen für Abfragen
Datenbanksystem (DB +DBMS)
Ein komplettes DBMS eingerichtet für den User gefüllt mit Daten und Tools für die Zugriffe.
Arten von Datenbanken
Heutzutage gibt es diverse Arten von Datenbanken:
Relationale Datenbanken: Tabellen sind über Schlüssel miteinander verknüpft. SQL wird zum Abfragen und Bearbeiten genutzt. (Ideal, wenn Daten strukturiert sind und klare Beziehungen haben.)
Objektorientierte Datenbanken: Daten werden als Objekte, wie bei Java oder C++, gespeichert. Objekte können Attribute und Methoden enthalten und komplexe Strukturen werden direkt gespeichert. (Ideal beim Arbeiten mit objektorientierten Programmiersprachen falls keine Umwandlung zwischen Objekt und Tabelle gewünscht ist.)
Dokumentenorientierte Datenbanken: Daten werden als Dokumente in JSON oder BSON gespeichert. Jedes Dokument kann unterschiedlich aufgebaut sein, wodurch diese Datenbanken für unstrukturierte und flexible Daten geeignet sind. Oft auch NoSQL genannt.
Hierarchische Datenbanken: Daten sind baumförmig organisiert, ähnlich eines Stammbaumes. Unflexibel bei Änderungen, dafür sehr schnell.
Codd-Regeln
Die Codd-Regeln sind 12 (oder 13 mit Regel 0) Regeln, die 1985 von E. F. Codd definiert wurden. Durch sie kann eine relationale Datenbank definiert werden.
Regel 0 (Hauptregel)
Ein relationales DBMS muss in der Lage sein, die gesamte Datenbank vollständig über seine relationalen Fähigkeiten zu verwalten.
Regel 1: Darstellung von Informationen
Alle Informationen in relationalen Datenbanken müssen logisch in Tabellen dargestellt sein.
Regel 2: Zugriff auf Daten
Jeder Wert in einer relationalen Datenbank muss logisch und eindeutig durch eine Kombination von Tabellenname, Primarschlüssel und Attributname (Spaltenname) auffindbar sein.
Regel 3: Systematische Behandlung von Nullwerten
Nullwerte stellen in Attributen, die nicht der Primärschlüssel sind, fehlende Daten dar und müssen in der gesamten Datenbank gleich behandelt werden.
Regel 4: Struktur einer Datenbank
Die Datenbankstruktur wird gleich wie die Daten gespeichert, ebenfalls in Tabellen. Somit muss die Struktur aller Tabellen in der Datenbank ebenfalls in einer Tabelle (dem Katalog) zugänglich sein. Eine Änderung in der Katalog-Tabelle entspricht somit automatisch einer Änderung in der Struktur der Datenbank.
Regel 5: Die Abfragesprache
Ein relationales System enthält mindestens eine befehlsgesteuerte Abfragesprache, welche folgende Funktionen unterstützt:
Datendefinition
Definition von Views
Definition von Integritätsbedingungen
Definition von Transaktionen
Definition von Berechtigungen
SQL (Structured Query Language) ist eine solche Sprache.
Regel 6: Aktualisieren von Views
Alle Views, die theoretisch aktualisiert werden können, müssen vom System aktualisierbar sein.
Regel 7: Abfragen und Bearbeiten ganzer Tabellen
Abfrage- und Bearbeitungsoperationen müssen als Operanden ganze Tabellen und nicht nur einzelne Datensätze umfassen können.
Regel 8: Physikalische Unabhängigkeit
Der Zugriff auf die Daten durch den Benutzer muss unabhängig davon sein, wie die Daten gespeichert werden. Anwendungen dürfen nur auf die logische Struktur des DBMS zugreifen. (Daten in einer Datenbank müssen auf der Festplatte nicht relational gespeichert sein - nur bei Abfragen / Interaktion mit den Daten muss dies der Fall sein.)
Regel 9: Logische Unabhängigkeit der Daten
Anwendungen und Zugriffe dürfen sich logisch nicht ändern, wenn Tabellen so geändert werden, dass alle Information erhalten bleiben (z. B. beim Aufspalten einer Tabelle in zwei Tabellen)
Regel 10: Unabhängigkeit der Integrität
Alle Integritätsbedingungen müssen in der Abfragesprache definierbar sein und in Tabellen dargestellt werden. Das System muss mindestens die folgenden Integritätsbedingungen prüfen:
Vollständigkeitsintegrität (Entity Integrity, Existential Integrity): Ein Primärschlüssel muß eindeutig sein und darf insbesondere keinen Nullwert enthalten.
Anwendungen für eine nicht-verteilte Datenbank dürfen sich beim Übergang zu einer verteilten Datenbank logisch nicht ändern. Sollte eine Datenbank also in einem Netzwerk auf zwei verschiedenen Rechnern Daten speichern, darf sich bei der Anwendung nichts ändern.
Regel 12: Unterlaufen der Abfragesprache
Unterstützt ein relationales Datenbanksystem neben der High-Level-Abfragesprache eine Low-Level-Abfragesprache, so darf diese die Integritätsbedingungen der High-Level-Sprache nicht unterlaufen. Die Low-Level Abfragesprache darf z. B. nicht direkt auf die physikalischen Eigenschaften der gespeicherten Daten zugreifen.
Anmerkungen
Viele Hersteller bezeichnen ihre Datenbanken als relational, auch, wenn nicht alle der 12 Regeln erfüllt sind.
Eigentlich gibt es seit 1990 333 Regeln, die Codd definierte.
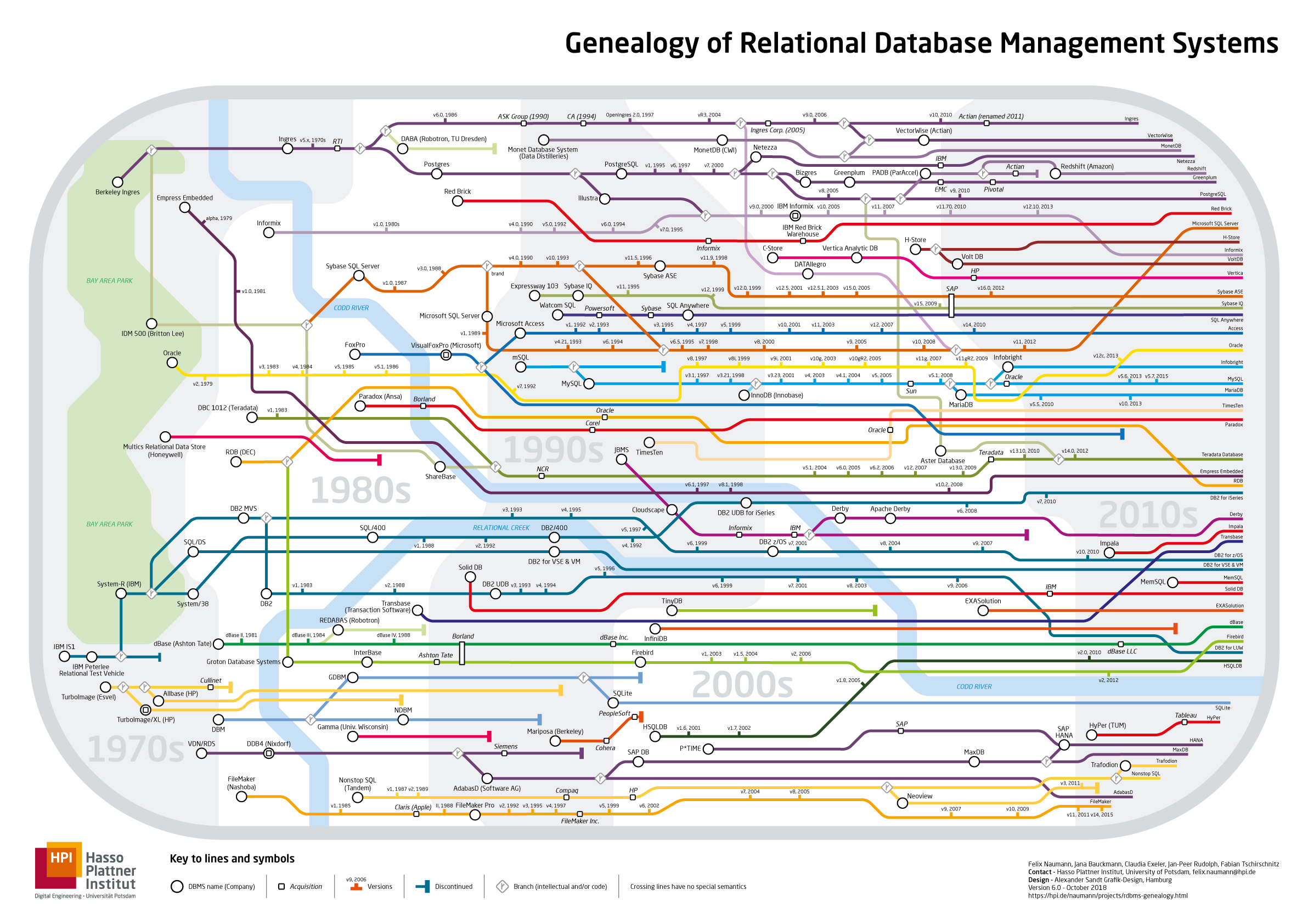
Entwicklung der verschiedenen Datenbanksysteme
Aufgaben eines DBMS
Die wesentlichen Funktionen von heutigen Datenbankmanagementsystemen sind:
Speicherung, Überschreibung und Löschung von Daten
Verwaltung der Metadaten
Vorkehrungen zur Datensicherheit, z.B. durch Backups
Vorkehrungen zum Datenschutz durch Benutzerverwaltung und Verschlüsselung
Vorkehrungen zur Datenintegrität / Konsistenz der Daten
Ermöglichung des Mehrbenutzerbetriebs durch Transactions
Optimierung von Abfragen
Ermöglichen von Triggern und Stored Procedures
Bereitstellung von Kennzahlen über Technik und Betrieb des DBMS
Bereitstellung von Statistikfunktionen, Berichtsfunktionen, Entwicklungsoberflächen, etc.
Normalisierung
Die Normalisierung stellt eine Möglichkeit zum Entwurf einer relationalen Datenbank dar. Eine Datenbank wird normalisiert, um keine Redundanzen zu haben und die Konsistenz in der Datenbank zu erhalten. Durch die Eliminierung von vervielfältigten Daten soll eine normalisierte Datenbank weniger Platz benötigen.
Es gibt 5 Normalformen:
1. Normalform
2. Normalform
3. Normalform
Boyce Codd Normalform
4. Normalform
1. Normalform
Jedes Attribut muss in atomarer Form vorliegen, es darf keine Wiederholungen geben. Eine Adresse beispielsweise ist kein Attribut - sie sollte aufgeteilt werden in Straße, Hausnummer, Postleitzahl, Ort, etc. Es darf auch keine Spalten geben, die die selbe Information doppelt speichern.
2. Normalform
Ist erreicht, wenn die 1. NF erreicht ist und jedes Attribut vom ganzen Schlüssel abhängt. Ziel ist, dass jede Reihe unterschiedliche Informationen enthält. Die Tabelle hier zeigt ein Negativbeispiel:
CD_ID
Albumtitel
Interpret
Erscheinungsjahr
Track
Titel
4710
I Don’t Mind
Anastacia
1998
1
Not That Kind
4711
Not That Kind
Anastacia
1999
2
I’m Outta Love
4711
Not That Kind
Anastacia
1999
3
Cowboys & Kisses
Im Beispiel hier Überlappen in der 2. und 3. Zeile die CD_ID, der Albumtitel und das Erscheinungsjahr - diese sollten nach Möglichkeit in unterschiedliche Relationen aufgeteilt werden, um doppelte Informationen zu vermeiden.
3. Normalform
Die dritte Normalform ist erreicht, wenn sich das Relationsschema in der zweiten Normalform befindet, und kein Nichtschlüsselattribut von einem anderen Nichtschlüsselattribut funktional abhängig ist.
Wenn z.B. in einer Tabelle die Postleitzahl als auch der Wohnort gespeichert werden, ist der Wohnort von der PLZ abhängig und kann in eine separate Tabelle ausgelagert werden.
Boyce Codd Normalform
Bei der Boyce Codd Normalform wird darauf geachtet, dass keine Attribute von anderen Attributen abhängig sind. Je nach Implementation kann dies unterschiedlich sein.
Negativbeispiel:
Veranstaltungstyp
Termin
Veranstaltung
Besichtigung
1.9.2019
Burgbesichtigung für Kinder
Besichtigung
4.9.2019
Burgbesichtigung für Senioren
Vortrag
6.9.2019
Vortrag der Tellerwäscher
Pro Termin gibt es nur einen Veranstaltungstyp, weshalb die Kombination dieser Attribute eindeutig ist. Theoretisch kann man den Veranstaltungstyp also in eine andere Tabelle auslagern und alles auf die Veranstaltung selbst beziehen.
4. Normalform
Verschärfung der Boyce-Codd-Form. Relationen in 4NF enthalten keine 2 voneinander
unabhängigen mehrwertigen Fakten.
Negativbeispiel:
PersonId
Sprache
Programmiersprache
Hobby
3
Englisch
Java
Lesen
3
Französisch
Python
Spielen
5
Griechisch
Pascal
Lesen
In diesem Beispiel haben Person 3 und Person 5 das selbe Hobby - diese Tabelle sollte also in 3 Relationen aufgeteilt werden:
Sollte eine Person also beispielsweise keine Programmiersprache kennen, können dafür einfach keine Daten eingefügt werden, was besser ist, als NULL einzutragen.
SQL-Basics
SQL ist eine Datenbanksprache zur Definition von Datenstrukturen in relationalen Datenbanken sowie zum Bearbeiten (Einfügen, Verändern, Löschen) und Abfragen von darauf basierenden Datenbeständen.
SELECT
Mithilfe des SELECT-Statements können Daten aus einer Datenbank gelesen werden. Das folgende SQL-Statement gibt alle Daten aus der Buch-Tabelle aus:
SELECT * FROM Book;
Hierbei werden alle Inhalte (Spalten und Zeilen) der Tabelle ausgegeben.
Einzelne Spalten
Es können auch nur einzelne Spalten ausgewählt werden:
SELECT title, price FROM Book;
DISTINCT
Falls nur unterschiedliche Datensätze ausgegeben werden sollen, kann zudem das DISTINCT-Keyword angegeben werden:
SELECT DISTINCT title FROM Book;
Falls der title bei mehreren Einträgen vorkommt wird er durch DISTINCT nur einmal ausgegeben.
UNION
Mithilfe von UNION können zwei SELECT-Statements kombiniert werden:
SELECT * FROM BookUNIONSELECT * FROM Author;
UNION filtert dabei automatisch doppelte Einträge, sollten sie existieren. Damit alle Einträge, auch doppelte, ausgegeben werden, kann UNION ALL verwendet werden. UNION ist aufgrund des Filtervorgangs langsamer als UNION ALL.
Common Table Expressions (CTE)
Mithilfe von Common Table Expressions (CTEs) können Ergebnisse eines SQL-Statements “zwischengespeichert” werden, um später in einem weiteren SQL-Statement erneut verwendet zu werden.
WITH ExampleTableExpression AS ( SELECT * FROM Buch WHERE ...) SELECT * FROM ExampleTableExpression;
Hierbei werden keine Daten zwischengespeichert - Das untere SELECT-Statement erhält nur die Daten aus der ExampleTableExpression CTE, als wären sie eine eigene Tabelle, bestehend aus den Daten des SELECT-Statements der CTE.
Aliase
Eine Spalte kann mithilfe des AS-Keywords mit einem anderen Namen ausgegeben werden:
SELECT title as book_title, price FROM Book;
Mehrere Tabellen
Selects können auch über mehrere Tabellen gehen:
SELECT * FROM Book, Author;
Falls nur bestimmte Spalten aus den jeweiligen Tabellen benötigt werden, können diese mit dem Tabellennamen davor angegeben werden:
SELECT Author.name, Person.name FROM Author, Person;
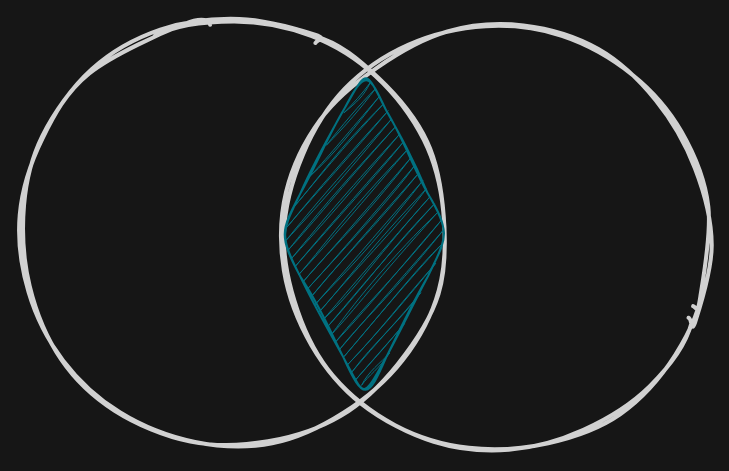
Verknüpfungen mit JOIN
Wenn zwischen zwei Tabellen Verknüpfungen existieren können diese mit JOIN ausgegeben werden.
Es gibt verschiedene Arten von Joins:
INNER JOIN/JOIN: Gibt die Schnittmenge aus und verknüpft über die Bedingung. Werte mit NULL werden ignoriert.
LEFT JOIN/RIGHT JOIN: Vereinigungsmenge basierend auf der linken oder rechten Tabelle. Wenn in der jeweils anderen Tabelle kein Datensatz dazu existiert, wird NULL angegeben.
FULL JOIN: Bildet die Vereinigungsmenge aus beiden Tabellen und füllt fehlende Werte mit NULL auf.
INNER JOIN/JOIN
LEFT JOIN
RIGHT JOIN
FULL JOIN
Filtern mit WHERE
Das Ergebnis eines Select-Queries kann mithilfe des WHERE-Keywords gefiltert werden. Das WHERE-Keyword muss nach der Tabellenangabe mit FROM stehen!
SELECT * FROM Book WHERE title = "Einhundertunddrei Bummsstellungen für Anfänger - Von Thomas Gottschalk";
Hier werden nur Bücher ausgegeben, deren title genau Einhundertunddrei Bummsstellungen für Anfänger - Von Thomas Gottschalk entspricht.
Aggretatfunktionen
Aggretatfunktionen können nicht innerhalb einer WHERE-Clause verwendet werden. Dafür wird das HAVING-Keyword benötigt.
HAVING
HAVING muss verwendet werden, wenn SQL-Abfragen mit Einschränkungen erstellt werden, bei denen Aggretatfunktionen zum Filtern genutzt werden, a das WHERE-Keyword diese nicht unterstützt:
SELECT AVG(price), country_of_origin FROM Book HAVING AVG(price) > 1 GROUP BY country_of_origin;
Vergleichen von Texten
Mithilfe von LIKE können Texte verglichen werden:
-- Groß- und Kleinschreibung egal:SELECT title FROM Book WHERE title LIKE "asterix";-- Mit Wildcard:SELECT title FROM Book WHERE title LIKE "aster%"; -- Auch "Asterix der Gallier" wird gefunden
Vergleichen von Datum
Daten können, gleich wie Zahlen, mithilfe von <, > und = verglichen werden:
SELECT release_date, title FROM Book WHERE release_date > "2000-01-01";
Vergleichen mit BETWEEN
Obwohl auch zwei Vergleiche mithilfe von < und > gemacht werden können, kann mit dem BETWEEN-Keyword eine Nummer effizienter verglichen werden:
SELECT price FROM Book WHERE price BETWEEN 10 AND 20;
Die Werte sind inklusive der Grenzen. Mithilfe von NOT BETWEEN können außerdem Werte außerhalb der Grenzen gesucht werden.
Verknüpfen von Bedingungen
Bedingungen können mithilfe von AND oder OR verknüpft werden:
SELECT * FROM Book WHERE price BETWEEN 10 AND 15 AND title LIKE "%asterix%";
Die Bedingungen werden dabei von links nach rechts gelesen.
NULL-Vergleiche
Mithilfe von IS NULL und IS NOT NULL können Werte auf NULL überprüft werden:
SELECT * FROM Book WHERE publisher IS NOT NULL;
Aggretatfunktionen
Mithilfe von Aggregatfunktionen können Statistiken direkt in der Datenbank berechnet werden.
MAX(): Gibt die maximale Zahl eines Select-Statements zurück
MIN(): Gibt die minimale Zahl zurück
SUM(): Gibt die Summe aller Zahlen zurück
AVG(): Gibt den Durchschnitt aller Zahlen zurück
STD(): Gibt die Standardabweichung zurück
VARIANCE(): Gibt die Varianz zurück
COUNT(): Gibt die Anzahl der Ergebnisse zurück
Um die Ergebnisse dieser Funktionen zu unterteilen, kann man die Ergebnisse mithilfe von GROUP BY gruppieren.
-- Maximaler Preis aller BücherSELECT MAX(price) FROM Books;-- Maximaler Preis aller Bücher in der jeweiligen SpracheSELECT MAX(price) FROM Books GROUP BY language;
Subqueries
Mithilfe von Subqueries können Filter dynamisch gemacht werden:
SELECT * FROM Book WHERE ( SELECT MAX(price) FROM Book) = ( SELECT MIN(price) FROM Book);
Die einzige Einschränkung hierbei ist, dass die Ergebnismenge auch ein Ergebnis enthalten muss.
Sortierung mit ORDER BY
Normalerweise werden Ergebnisse in der selben Reihenfolge ausgegeben, wie sie in der Datenbank vorliegen. Mithilfe von ORDER BY ... ASC | DESC kann die Sortierung jedoch nach einem bestimmten Schlüssel in aufsteigender oder abfallender Reihenfolge geschehen:
-- Sortiere nach TitelSELECT title FROM Book ORDER BY title ASC;-- Sortire nach Titel, bei selbem Titel nach UntertitelSELECT title, subtitle FROM Book ORDER BY title, subtitle ASC;
INSERT
Mit INSERT werden Datensätze in eine Tabelle eingefügt. Dabei können die Datensätze direkt angegeben werden oder aus einem SELECT-Query resultieren. Insofern keine Spalten manuell angegeben werden müssen die Werte in der gleichen Reihenfolge wie bei der Tabellendefinition angegeben werden.
-- Ohne SpaltenINSERT INTO Keyword VALUES (195, "Information Technology");-- Mit SpaltenINSERT INTO Keyword (book_id, name) VALUES (195, "Information Technology");-- Mit Werten aus einem anderen SELECT-QueryINSERT INTO Keyword (book_id, name) SELECT book_id, "Linux" FROM Book WHERE title LIKE "%Linux%";
UPDATE
Wenn ein Datensatz geändert werden soll, muss UPDATE verwendet werden.
-- Update einer einzelnen SpalteUPDATE Publisher SET Publisher.zip_code = 88045 WHERE Publisher.city = "Friedrichshafen";-- Update mehrerer SpaltenUPDATE Publisher SET Publisher.zip_code = 88045, Publisher.street_name = "Musterstraße" WHERE Publisher.city = "Friedrichshafen";
DELETE
Mit DELETE werden Datensätze gelöscht.
-- Löscht aller BücherDELETE FROM Book;-- Löscht alle Bücher mit "Windows" im TitelDELETE FROM Book WHERE title LIKE "%Windows%";
Objektmanipulation
DATABASE
Eine leere Datenbank kann folgendermaßen erstellt werden:
CREATE DATABASE DatabaseName;
Um die Datenbank zu verwenden, muss USE verwendet werden:
USE DatabaseName;
Insofern noch keine Datenbank ausgewählt ist, können trotzdem bereits SELECT-Anfragen gestellt werden:
SELECT * FROM BookDatabase.Book;
Eine Datenbank kann mit DROP gänzlich gelöscht werden:
DROP DATABASE DatabaseName;
Ändern kann man eine Datenbank nicht.
TABLE
Tabellen können ebenfalls mit CREATE erstellt werden:
CREATE TABLE IF NOT EXISTS TableName ( ColumnName Datatype, ..., PRIMARY KEY (SomeDefinedColumnName), FOREIGN KEY (SomeDefinedColumnName),)
In diesem Fall wird aufgrund von IF NOT EXISTS kein Fehler gemeldet, wenn die Tabelle bereits existiert. Die neue Tabelle wird nur angelegt, falls noch keine vorliegt. Mit CREATE OR REPLACE TABLE kann eine Tabelle auch einfach überschrieben werden, sollte sie bereits existieren. Tabellen können außerdem umbenannt werden:
RENAME TABLE OldTableName TO NewTableName;
Mit DROP TABLE kann eine Tabelle gänzlich gelöscht werden und mit ALTER TABLE kann eine Tabelle modifiziert werden, ohne die Daten selbst zu löschen. Es gibt folgende Möglichkeiten, eine Tabelle zu bearbeiten:
Mit ADD können Spalten, Indexe und Keys hinzugefügt werden
Mit DROP können Spalten, Indexe und Keys gelöscht werden
Mit MODIFY können Spalten, Indexe und Keys geändert werden.
ALTER TABLE BooksADD COLUMN example_col VARCHAR(255);ALTER TABLE BooksMODIFY COLUMN example_col VARCHAR(100);ALTER TABLE BooksDROP COLUMN example_col;-- Kombiniert in einem Statement:ALTER TABLE BooksADD COLUMN example_col_1 VARCHAR(255),MODIFY COLUMN example_col_2 VARCHAR(100),DROP COLUMN example_col_3;
VIEW
Ein VIEW ist eine Sicht auf eine oder mehrere Tabellen, ähnlich einem Filter. Bei einem View werden keine Daten gespeichert, sondern berechnete Daten angezeigt. Die Daten werden erst berechnet wenn der View aufgerufen wird.
Ein View kann folgendermaßen erstellt werden:
CREATE VIEW ExampleView ASSELECT * FROM Table; -- Hier muss einfach nur ein normales SELECT-Statement stehen!
Views können dann via normalem SELECT-Query aufgerufen werden:
SELECT * FROM ExampleView;
Um einen View zu bearbeiten muss man das SELECT-Query erneut angeben. Löschen kann man Views mit DROP.
ALTER VIEW ExampleView ASSELECT * FROM Table;DROP VIEW ExampleView;
INDEX
Indizes sind interne Listen, die bei Abfragen helfen können, die Anfrage schneller zu verarbeiten. Sie machen SELECT-Queries schneller, verlangsamen aber INSERT-, UPDATE- und DELETE-Queries. Außerdem verbrauchen sie viel Speicherplatz. Indizes können beim Erstellen einer Tabelle oder separat angelegt werden:
-- Bei Erstellung der TabelleCREATE TABLE TableName ( ExampleColumn VARCHAR(255) NOT NULL, ExampleId int NOT NULL AUTO_INCREMENT, PRIMARY KEY (ExampleId) INDEX IndexName (ExampleColumn));-- SeparatCREATE INDEX IndexName ON TableName (ExampleColumn);
Ein Index, zumindest in MySQL, kann nicht geändert werden, sondern muss mit DROP gelöscht und danach neu angelegt werden:
DROP INDEX IndexName ON TableName (ExampleColumn);
Bei Abfragen kann der Datenbank ein Index vorgeschlagen werden, der genutzt werden soll. Ebenso kann man einen Index erzwingen und ausschließen:
SELECT * FROM TableName USE INDEX (ExampleColumn) WHERE ExampleColumn LIKE "%ExampleText%";SELECT * FROM TableName FORCE INDEX (ExampleColumn) WHERE ExampleColumn LIKE "%ExampleText%";SELECT * FROM TableName IGNORE INDEX (ExampleColumn) WHERE ExampleColumn LIKE "%ExampleText%";
EVENT
Events sind SQL-Anweisungen für die Datenbank, die von der Datenbank entweder zu einem bestimmten Zeitpunkt oder in einem Interval selbstständig ausgeführt werden können.
Syntax:
CREATE EVENT EventName
ON SCHEDULE [AT timestamp | EVERY interval]
DO
[SQL-Anweisung]
Beispiel:
CREATE EVENT CleanupEventON SCHEDULE EVERY 1 HOURDO UPDATE SomeDatabase.SomeTable SET SomeColumn = SomeColumn + 1 WHERE SomeID = 5;
Transaktionen mit TRANSACTION
Mithilfe von Transaktionen kann sichergestellt werden, dass mehrere SQL-Queries zusammen ausgeführt werden. Wenn eines der SQL-Queries in einer Transaktion fehlschlägt werden alle SQL-Queries, die innerhalb der Transaktion ausgeführt wurden, rückgängig gemacht.
Ein klassisches Beispiel für eine Transaktion ist eine Überweisung von einem Bankkonto auf ein anderes. Bei solch einer Überweisung müssen mehrere Tabellen bearbeitet werden, meist separat. Natürlich sollte keine der Anfragen hierbei mittendrin einfach fehlschlagen. Eine Transaktion ist hier eine optimale Lösung:
BEGIN TRANSACTION; UPDATE Accounts SET balance = balance - 150WHERE AccountID = 1; UPDATE Accounts SET balance = balance + 150WHERE AccountID = 2; COMMIT;
Mithilfe von ROLLBACK kann die Transaktion auch manuell zurückgesetzt werden:
BEGIN TRANSACTION; UPDATE Accounts SET balance = balance - 150WHERE account_id = 1;UPDATE Accounts SET balance = balance + 150WHERE account_id = 2; ROLLBACK;
Außerdem können innerhalb einer Transaktion sogenannte SAVEPOINTs erstellt werden, zu denen bei einem Rollback gesprungen werden kann:
BEGIN TRANSACTION; UPDATE Accounts SET balance = balance - 150WHERE account_id = 1;SAVEPOINT sp1;UPDATE AccountsSET balance = balance + 150WHERE account_id = 2;ROLLBACK TO sp1;COMMIT;
In diesem Beispiel würde nur das Geld abgezogen werden - User 2 würde kein Geld erhalten.
Good to know:
Standardmäßig erstellt die Datenbank im Hintergrund selbst eine Transaktion, auch für einzelne Queries.
Trigger
Ein Trigger ist ein Objekt in einer Datenbank, welches eine Nutzer-definierte Funktion ausführt, wenn ein bestimmtes Event in einer Tabelle passiert.
Die Syntax zum Erstellen eines Triggers lautet:
CREATE TRIGGER trigger_name
[BEFORE|AFTER] event
ON table_name trigger_type
BEGIN
-- trigger_logic
END;
event kann z.B. SELECT, INSERT oder UPDATE sein
table_name ist der Name der Tabelle, auf den der Trigger reagieren soll
trigger_type kann entweder FOR EACH ROW oder FOR EACH STATEMENT sein
-- trigger_logic ist ein Platzhalter, in dem SQL verwendet werden kann
Der Primärschlüssel einer Relation kann unterschiedlich aufgebaut sein. Man unterscheidet zwischen eindeutigen, zusammengesetzten und künstlichen Primärschlüssel.
Schlüssel ist das Suchkriterium, er ist pro Datensatz eindeutig.
Index ist eine sortierte Pointerliste.
Das für den Index verwendete Suchkriterium nennt man den Schlüssel des Indexes.
Oft ist der Primärschlüssel identisch mit dem Primärindex.
Es gibt verschiedene Arten von Indizes:
ISAM: Daten werden sortiert und in festen Seiten gespeichert, der Index verweist direkt auf diese Seiten. Neue Einträge landen in Overflow-Bereichen, wodurch die Performance bei vielen Änderungen sinkt.
B-Baum: Ein selbstbalancierender Baum, bei dem Schlüssel und Datensätze in allen Knoten gespeichert sein können. Einfügen und Löschen halten den Baum automatisch ausgeglichen.
B+ Baum: Eine Variante des B-Baums, bei dem alle Datensätze nur in den Blattknoten liegen, die zusätzlich verkettet sind. Dadurch sind Bereichsanfragen besonders effizient.
Hashing: Ein Hashwert wird aus dem Suchschlüssel berechnet, der direkt auf die Speicherposition verweist. Sehr schnell für exakte Suchen, aber ungeeignet für Bereichsabfragen.
Indexart
Vorteile
Nachteile
ISAM
• Sehr schnelle Lesezugriffe bei statischen Daten • Einfache Struktur • Gut für sequentielle Zugriffe
• Schlechte Performance bei vielen Inserts • Overflow-Bereiche können lang werden • Keine automatische Reorganisation
B-Baum
• Automatisch balanciert • Gut für Lese- und Schreibzugriffe • Unterstützt Bereichsanfragen
• Etwas komplexer Aufbau • Datensätze auch in inneren Knoten
B+-Baum
• Sehr effizient für Bereichsanfragen • Alle Daten nur in Blättern • Blätter sind verkettet
• Mehr Speicherbedarf • Etwas teurer beim Einfügen/Löschen
Hashing
• Extrem schnelle exakte Suchen (O(1)) • Einfaches Prinzip
• Keine Bereichsanfragen möglich • Kollisionen möglich • Reihenfolge der Daten geht verloren
Benutzer und Rechte
Die Rechte des Datenbankservers unterscheiden sich von dem des Betriebssystems und werden in der Datenbank selbst verwaltet und gespeichert.
USER
In jeder Datenbank können Nutzer mithilfe von CREATE USER erstellt werden. Mithilfe von DROP USER kann ein Nutzer auch wieder gelöscht werden.
CREATE USER ExampleUsername IDENTIFIED BY "ExamplePassword";DROP USER ExampleUsername;
Rollen
Mithilfe einer Rolle können “Nutzergruppen” definiert werden. Einer Rolle können, gleich wie einem Nutzer, Rechte zugewiesen werden. Die Rolle selbst kann dann einem oder mehreren Nutzern zugewiesen werden, was das Management von Rechten vereinfacht.
CREATE ROLE ExampleRole;
Rechte können mit GRANT vergeben werden. Um einer Rolle beispielsweise das Lesen und Einfügen in einer Tabelle zu erlauben, kann folgendes Query verwendet werden:
GRANT SELECT, INSERT ON ExampleTable TO ExampleRole;
Eine Rolle kann schließlich einem Nutzer mit GRANT zugewiesen werden:
GRANT ExampleRole to ExampleUser;
Mehrere Rollen pro Nutzer
Ein Nutzer kann mehrere Rollen besitzen, allerdings immer nur eine Rolle gleichzeitig verwenden. Der Nutzer muss seine Rolle selbst mit SET ROLE auswählen.
Wenn ein Nutzer eine Rolle standardmäßig verwenden soll, kann SET DEFAULT ROLE verwendet werden:
SET DEFAULT ROLE ExampleRole TO ExampleUser;
Man kann Rechte auch direkt einem Nutzer zuweisen.
Entfernen von Rechten
Mithilfe von REVOKE kann man Rechte von einem Nutzer entfernen.
-- Zeige alle Rechte für einen Benutzer anSHOW GRANT FOR ExampleUser;-- Entferne eine BerechtigungREVOKE SELECT ON ExampleTable FROM ExampleUser;
Privilegien
Mit ALL PRIVILEGES kann ein Nutzer Zugriff auf alle Funktionen für das angegebene Object gewährt werden:
GRANT ALL PRIVILEGES ON ExampleTable TO ExampleUser;-- Equivalent zuGRANT SELECT, INSERT, UPDATE, DELETE ON ExampleTable TO ExampleUser;
GRANT OPTION
Mit WITH GRANT OPTION kann man einem Nutzer das Recht geben, seine eigenen Berechtigungen an andere Nutzer weiterzugeben.
GRANT SELECT ON ExampleTable TO ExampleUser WITH GRANT OPTION;
Objekte
Für die folgenden Objekte können Privilegien vergeben werden:
Global
Für einzelne Datenbanken
Für einzelne Tabellen
Für einzelne Spalten
Für Funktionen und Prozeduren
-- GlobalGRANT SELECT ON *.* To ExampleUser;-- Für eine DatenbankGRANT SELECT ON DatabaseName TO ExampleUser;-- Für eine Tabelle, implizit und explizitGRANT SELECT ON TableName TO ExampleUser;GRANT SELECT ON DatabaseName.TableName TO ExampleUser;-- Für eine SpalteGRANT SELECT ON DatabaseName.TableName(Column1, Column2) TO ExampleUser;
Passwörter
Man kann das Passwort für einen Nutzer wie folgt ändern:
SET PASSWORD FOR ExampleUser = PASSWORD("plaintext password");
Backup und Recovery
Fehler mit Hauptspeicherverlust
→ Stromausfall, Rechnerabstürze. Nur Daten im RAM sind verloren gegangen, noch nicht zur Disk geschrieben. Die Logs existieren aber.
Das Transaktionsparadigma verlangt aber:
alle Änderungen, die schon in die materialisierte Datenbasis eingebracht wurden durch nicht abgeschlossene Transaktionen müssen rückgängig gemacht werden.
alle Änderungen, die noch nicht in der materialisierten Datenbasis stehen, deren Transaktionen aber abgeschlossen sind, müssen nachvollzogen werden.
⇒ Zuerst muss ein (globales) Undo, dann ein (globales) Redo ausgeführt werden:
Fehler mit Hintergrundspeicherverlust
→ Plattencrash, Feuer, Überspannung
Solche Fehler sind zwar selten, allerdings sollten gegen sie Vorkehrungen getroffen werden. Hierzu werden Backups mit Logdateien benötigt.
Backupstrategien
Beim Ausdenken einer Backupstrategie sollte man sich folgende Fragen stellen:
Wie lange darf die Wiederherstellung dauern?
Kann die Datenbank offline gesichert werden?
Wie groß ist das zu erwartende Datenvolumen?
Was steht an Geld und Ressourcen zur Verfügung?
Arten von Backups
Physisch vs. Logisch
Ein physisches Backup sichert die Datenbankdateien, also Daten, Strukturdateien, RedoLogDateien, Kontrolldateien, je nach Datenbank. Ein logisches Backup speichert die Funktionen um die Datenbankobjekte zu erzeugen und die
INSERT-Statements für die Daten.
Phsyisches Backup
Logisches Backup
Geschwindigkeit
Schneller
Langsamer
Dateigröße
Kompakt
Größer
Portierbarkeit
Nur auf identische Maschinen
Portabel
Online?
Nein
Ja
Partiell vs. Komplett
Ein Backup kann entweder nur einen Teil der Datenbank oder die gesamte Datenbank umfassen. Ein logische partielle Sicherung wäre z.B. nur die eine Tabelle mit ihrem CREATE-Statement und den INSERTs für die Daten. Ein physisches, partielles Backup wäre nur die Sicherung der Strukturdateien ohne die Log-Dateien.
Inkrementell vs. Voll
Das Backup kann inkrementell oder voll gamcht werden. Inkrementell bedeutet, dass nur die Daten seit dem letzten Backup gesichert werden. Dabei benötigt man die letzten Backups, allerdings ist es deutlich Schneller.
Online vs. Offline
Backups können bei laufendem Datenbankserver (online) und laufendem Betrieb gemacht
werden, oder bei geschlossenem System (offline), was bedeutet, dass während des Backups keine Anfragen gestellt werden können.
Zeitpunkt des Backups
Regelmäßig sollten Backups der gesamten Datenbank erstellt werden. Bei Strukturänderungen, vor sowie nach dem Einspielen von Upgrades und nach Transaktionen ohne Logging sollten ebenfalls Backups erstellt werden.
Ort des Backups
Folgende fünf Fragen können bei der Entscheidung von Medium und Ablageort helfen:
Auf welchem Medium speichere ich das Backup?
Wie teuer ist das Backup und das Medium?
Wie lange muss ein Backup erhalten bleiben?
Wo wird das Backup abgelegt?
Wie lange darf eine Wiederherstellung dauern?
Mögliche Medien
Medium
Lebensdauer
Externe Festplatten
5-10 Jahre, je nach Nutzung
Flash-Speicher (USB, SSD)
5-10 Jahre
Magnetband
30-50 Jahre
Optische Medien (CD, DVD)
Abhängig von Lagerung, höchstens 30 Jahre
Cloud
Nicht bekannt
Recovery
Es sollte regelmäßig überprüft werden, ob die gespeicherten Backups funktionieren. Sowohl die Erstellung des Backups als auch die Wiederherstellung sollten getestet und Dokumentiert werden.
CRUD
CRUD steht für Create, Read, Update, Delete. CRUD definiert die Operationen, die in einer relationalen Datenbank verfügbar sind. Mithilfe von INSERT, SELECT, UPDATE und DELETE können die jeweiligen Operationen in SQL durchgeführt werden.
ACID
ACID steht für Atomicity, Consistency, Integrity und Durability während einer Transaktion.
Atomicity: Bei einer Transaktion müssen alle oder keine Aktionen durchgeführt werden
Consistency: Die Datenbank muss sich vor, während und nach einer Transaktion in einem validen Zustand befinden
Isolation: Transaktionen müssen unabhängig voneinander behandelt werden
Durability: Änderungen während einer Transaktion müssen permanent gespeichert werden.
Die ACID-Prinzipien sollen dabei helfen, Datenintegrität und Datenkorruption bei Transaktionen zu verhindern.
Deadlocks
Ein Deadlock passiert, wenn in einer Mehrbenutzerdatenbank sich zwei oder mehr Transaktionen gegenseitig Blockieren, da sie die Ressourcen blockieren, die die jeweils andere Transaktion verwenden will. Ein DBMS erkennt in der Regel solche Deadlocks und bricht eine der Transaktionen ab, um das Deadlock aufzulösen.