Max. Datenrate auf einem Übertragungskanal Die zeitliche Länge eines Symbols bestimmt die Anzahl der Bits, die pro Zeiteinheit übertragen werden können. Die Übertragungsrate eines Kanals ist dann gegeben durch die Symbolrate , also die Anzahl der Symbole pro Sekunde mal der Anzahl an Bits , die pro Symbol transportiert werden können:
Maßeinheiten für die Bandbreite / Übertragungsraten Übertragungsraten werden in Bit pro Sekunde oder angegeben, als 10-er Potenzen. , , etc. Speicherkapazitäten für Festplatten werden in Bytes () angegeben, als 2-er Potenzen. , , …
Latency und Round Trip Time (RTT) Die Laufzeit der Pakete von einem Unternehmensnetzwerk in den Backbone des Internets bestimmt neben der Übertragungsrate die Leistungsfähigkeit des Internetanschlusses. Die Zeiten unterscheiden sich je nach Technik, Entfernung zum Edge-Router des ISPs und Anzahl der ISP-Hops. Diese Zeiten lassen sich durch die Paket-Umlaufzeit oder durch die sog. Latenz messen.
Leitungsvermittlung vs Paketvermittlung
| Vermittlungsart | Vorteile | Nachteile |
|---|---|---|
| Leitungsvermittlung | - Ressourcen werden vorab reserviert - Garantierte Dienstgüte (QoS) | - Blockiert Ressourcen für gesamte Dauer - Andere Teilnehmer können Ressourcen nicht nutzen |
| Leitungsvermittlung auf geteilten Leitungen | - Nutzung vorhandener Leitungen durch mehrere Verbindungen möglich | - Nachteile wie bei Leitungsvermittlung, aber zusätzliche Konkurrenz um Leitung |
| Paketvermittlung | - Bessere Ressourcenauslastung - Kanal nur kurz pro Paket belegt - Flexible Weiterleitung über Router | - Overhead durch Header - Keine garantierte Dienstgüte ohne zusätzliche Mechanismen |
| Statistisches Multiplexing | - Sehr effiziente Ressourcennutzung - Mehr Benutzer gleichzeitig - Kapazität wird nach Bedarf zugeteilt | - Wettbewerbs- und Queuing-Verzögerungen - Bei Überlast: Paketverlust oder hohe Latenz |
Beschreibung von Nutzung durch Binomialverteilung:
steht für Wahrscheinlichkeit, dass Nutzer gleichzeitig aktiv sind. ist die Gesamtzahl der Teilnehmer im Netzwerk, die gleichzeitig aktive Nutzer, für die Wahrscheinlichkeit, dass ein Nutzer sendet. Mittlere Anzahl an gleichzeitig sendenden Benutzern: , wobei
⇒ , . Im Idealfall sendet nur ein Teilnehmer.
Berechnung von Benutzern bei Vermittlungsarten Leitungsvermittlung: Paketvermittlung: , ,
Paketvermittlung: Store-and-Forward-Verzögerung Bei Packet-Vermittlung werden eingehende Packets werden erst nach vollständigem Eingang weitergeleitet - Es entsteht also eine Verzögerung. Jedes Packet muss auf die nächste Leitung mit der Übertragungsrate erneut übertragen werden:
Hierbei ist die Packet size in Bytes und die Übertragungsrate in bit/s der Leitung. Bei Routern ergibt sich eine Gesamtverzögerung von .
Ausbreitungsverzögerung in einem Medium
ist die Distanz, die Geschwindigkeit im Medium
Wartezeit in Puffern ist die Bandbreite der Leitung, die durchschnittliche Paketgröße, die durchschnittliche Paketankunftsrate und ist der Verkehrswert.
⇒ sollte immer deutlich kleiner 1, meist kleiner 0,7 sein, da sonst die Wartezeit exponentiell steigt.
Gesamtverzögerung auf einem Leitungssegment
ist meist wenige Mikrosekunden groß und daher vernachlässigbar. steht für die wartezeit in Puffern , für die Übertragungsverzögerung. Sie ist signifikant wenn klein () ist. (Signifikant wenn groß.)
Durchsatz in Netzwerken
- Durchsatz : Datenrate, mit der Daten zwischen Daten zwischen Sender und Empfänger ausgetauscht werden:
- Unmittelbar: ⇒ Datenrate zu einem gegebenen Zeitpunkt ()
- Durchschnittlich: ⇒ Mittlere Rate über längeren Zeitraum
- Die Leitung auf dem Pfad, die die geringste Übertragungsrate besitzt, begrenzt den Datendurchsatz
Durchsatz in Netzwerken Der Datenverkehr zwischen Clients und Server muss den Backbone des Netzwerkes durchlaufen. Der mittlere maximale Durchsatz für eine Ende-zu-Ende-Verbindung zwischen einem Client und einem Server bei gleichzeitigen Verbindungen im Backbone kann berechnet werden durch:
Hierbei steht für die Rate des Clients, für die Rate des Servers, für die Rate des Backbones und für die Anzahl Nutzer im Backbone.
⇒ muss größer/gleich sein!
TCP vs UDP TCP ist ein Protokoll für den zuverlässigen Transport von Nachrichten zwischen Prozessen. Es implementiert Flusskontrolle zur Anpassung der Datenrate des Senders an Verarbeitungsgeschwindigkeit des Empfängers sowie *Überlastkontrolle, wobei der Sender seine Datenrate an die Kapazität des Netzwerks anpasst.
UDP ist ein Protokoll für den Best Effort Transport zwischen Prozessen. Es bietet keine Kontrollen, Orientierungen oder Zeit-/Bandbreitengarantien. UDP existiert wegen höherer Übertragungsrate, da keine Verbindung zwischen Client und Server aufgebaut wird, und keine Kontrollen existieren, die Datenraten ausbremsen. Es wird hauptsächlich bei VoIP und VCoIP (Video Conferencing over IP) verwendet.
Schichten Schicht 1: Bitübertragungsschicht, Schicht 2: Sicherungsschicht, Schicht 3: Vermittlungsschicht, Schritt 4: Transportschicht, Schritt 5: Sitzungsschicht, Schritt 6: Darstellungsschicht, Schritt 7: Anwendungsschicht
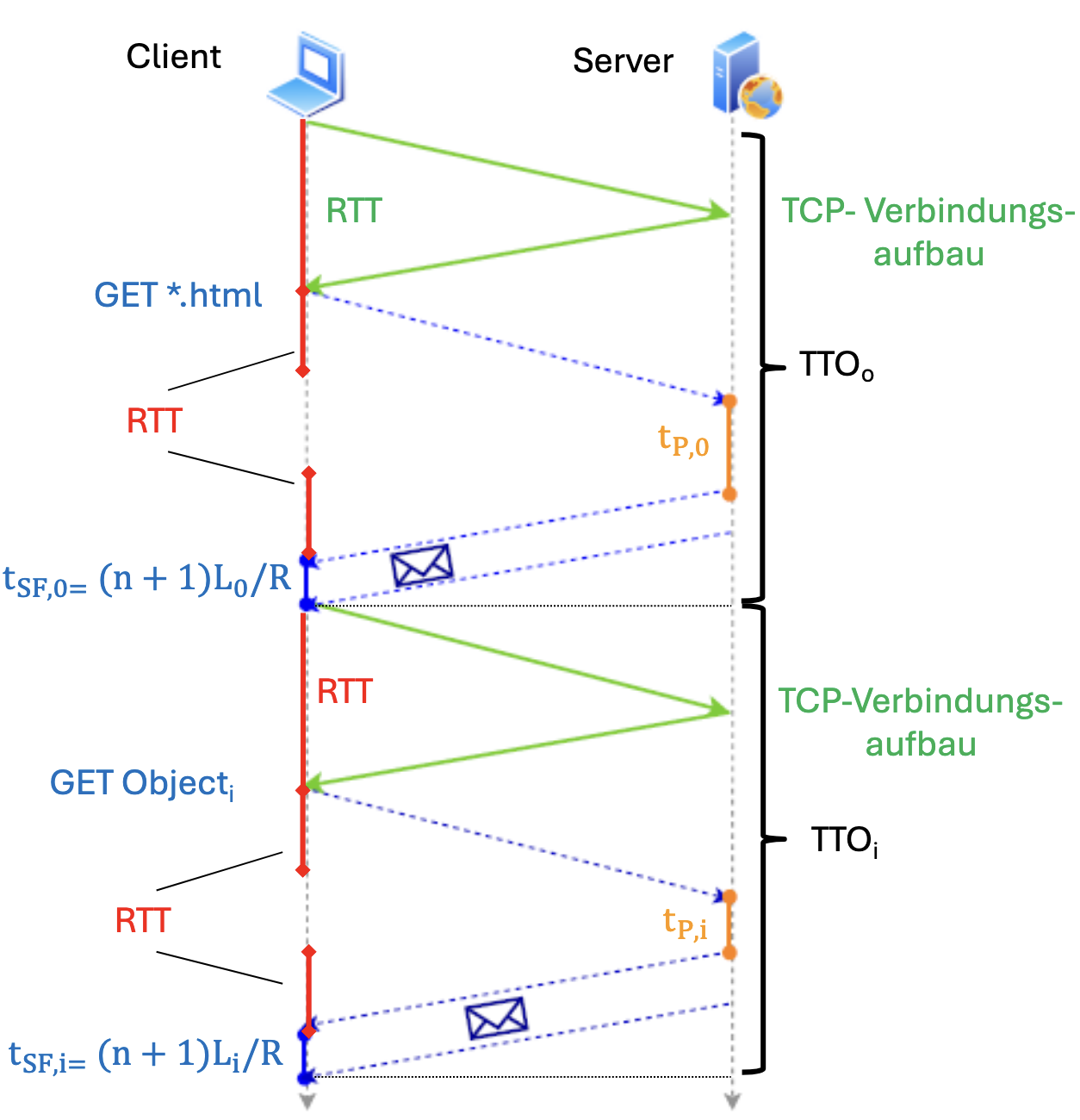
Nicht persistentes HTTP Berechnung für gesamte Übertragungszeit für Website mit Objekten der Größe :
- Eine für TCP-Verbindungsaufbau und eine für Homepage werden benötigt
- Außerdem muss die Übertragungsverzögerung bei Bandbreite und Hops mitberechnet werden
Zeit des Servers, um Daten bereitzustellen:
Bei Objekten:
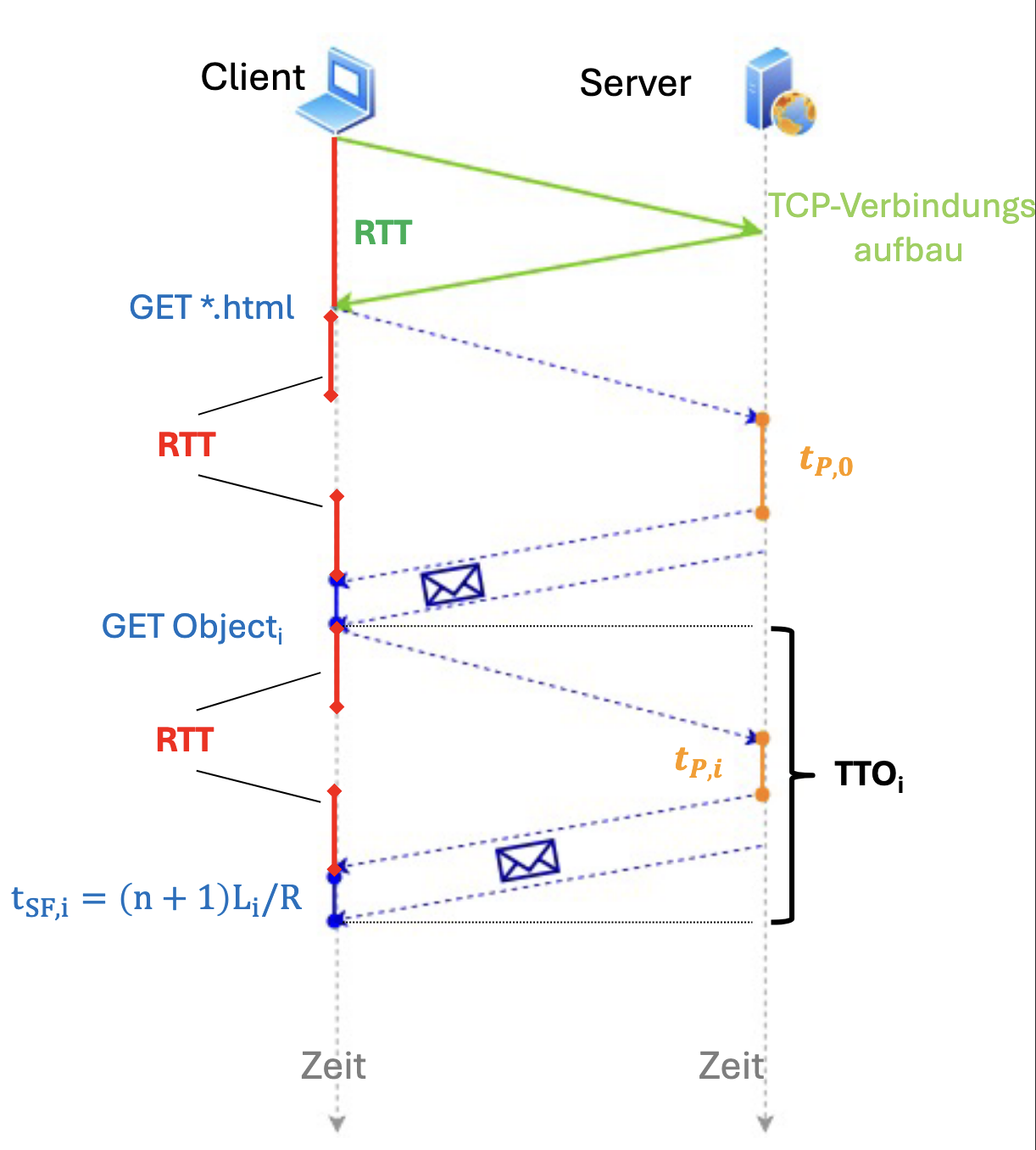
Persistentes HTTP ohne Pipelining Bei Persistentem HTTP wird nur eine TCP-Verbindung gebraucht, die mehrmals verwendet wird.
Summation:
⇒ Persistenz führt zu einer Halbierung der Übertragungszeit.
Persistentes HTTP mit Multiplexing Eine TCP Verbindung mit Multiplexing wird verwendet. Hierbei werden HTTP Requests und Responses in kleine Teile mit Headern zerlegt, können also parallel ohne Reihenfolgezwang und ohne Blockierung übertragen werden. Jede Teilnachricht erhält eine Stream-ID und kann vom Client wieder zusammengesetzt werden.
Persistentes HTTP mit Pipelining Auch hier wird nur eine TCP Connection verwendet. Der Browser kann zudem per HTTP-Request mehrere Objekte nacheinander anfragen. Der Webserver antwortet in der gleichen Reihenfolge, in der die Anfragen empfangen wurden.
Bei Objekten:
Erklärung:
- : Entfernung zum Web-Server
- : Anzahl der Objekte
- : Leistungsfähigkeit des Web-Servers
- , : Route im Internet, Anzahl der Hops und Bandbreite der Leitung zwischen zwei Hops
- : Größe der Objekte
| Nicht persistentes HTTP | Persistentes HTTP ohne Pipelining |
|---|---|
 |  |
| Persistentes HTTP mit Multiplexing |
|---|
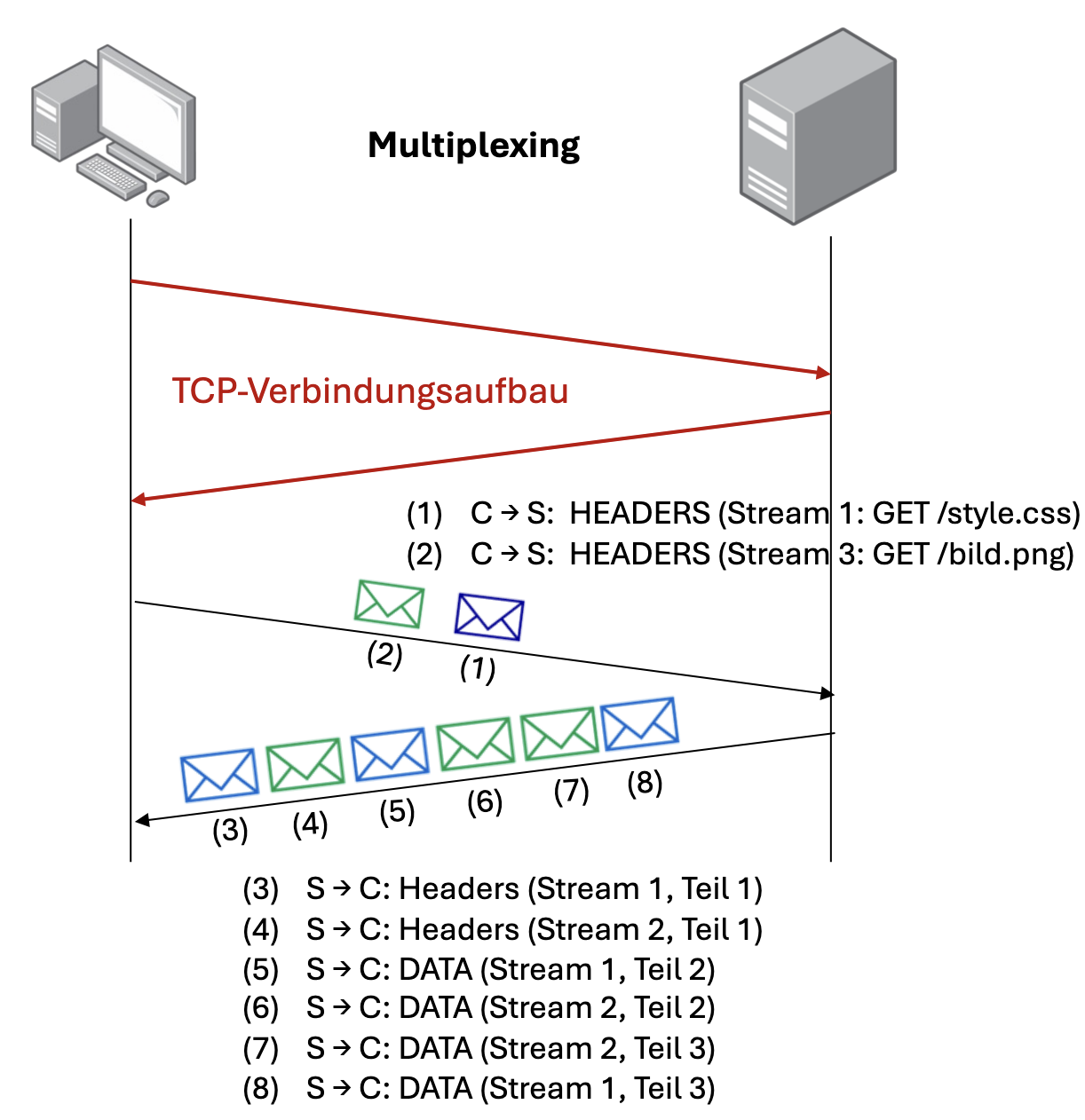 |
Head of Line-Blockierung: Server bearbeitet Anfragen nach FCFS-Prinzip (First come, first served). Bei FCFS müssen kleine Objekte evtl. auf die Übertragung eines größeren Objektes warten.
HTTP/2: Multiplexing Bei Objekten bestimmt aufgrund von Multiplexing das größte Objekt die Gesamtübertragungszeit. Es wird auch hier eine einzige TCP Session verwendet.
- 2 für Verbindungsaufbau
- 1 für Bereitstellung aller Objekte
Es gibt weitere Optimierungen:
- Header Compression führt zu Reduktion von
- Server-Push: Server analysiert HTML und schickt proaktiv die benötigten Webobjekte (3 → 2 )
2.3 TLS (Transport Layer Security) Problem: Anwendungsschichtprotokolle verwenden Daten unverschlüsselt und ohne Schutz gegen Veränderungen über das Internet. Lösung: Transportsicherheitsprotokoll TLS in Sitzungs- und Darstellungsschicht. Port 80 für HTTP-Kommunikation im Klartext, 443 für HTTPS mit TLS.
TLS besteht aus zwei Teil-Schichten und 6 Protokollen: Dem Alert Protocol für Fehlerbehandlung, dem Heartbeat Protocol zum Prüfen, ob Partner einer TLS-Verbindung noch aktiv ist, dem Handshake Protocol zum Aushandeln von kryptografischen Schlüsseln und Integritätssicherung, dem ChangeCipherSpec Protocol zur Aktivierung der Verschlüsselung und Integritätssicherung, dem Application-Data-Protocol, welches HTTP-Daten aus Applikationsschicht entgegennimmt und transparent weiterleitet, sowie dem Record Layer Protocol, welches die vom ADP weitergereichten Daten in Form eines TLS-Fragment fragmentiert, komprimiert, sichert und verschlüsselt.
Das Handshake Protocol, welches Server auf Basis von digitalen X.509-Zertifikaten authentifiziert und kryptografische Algorithmen und Schlüssel für Verschlüsselung und Integrity-Checks aushandelt, sowie das Change Cipher Spec Protocol, welches die Verschlüsselung auf Server und Client aktiviert, *sind für Sicherheit zuständig. Für Stabilität sind das Heartbeat Protocol, welches alle 30 - 60 Sekunden eine Hearbeat-Request an den anderen Teilnehmer sendet, um zu sehen, ob dieser noch aktiv ist, und das Alert Protocol, welches der Behandlung von Fehlern dient, zuständig.
Record Layer Protocol
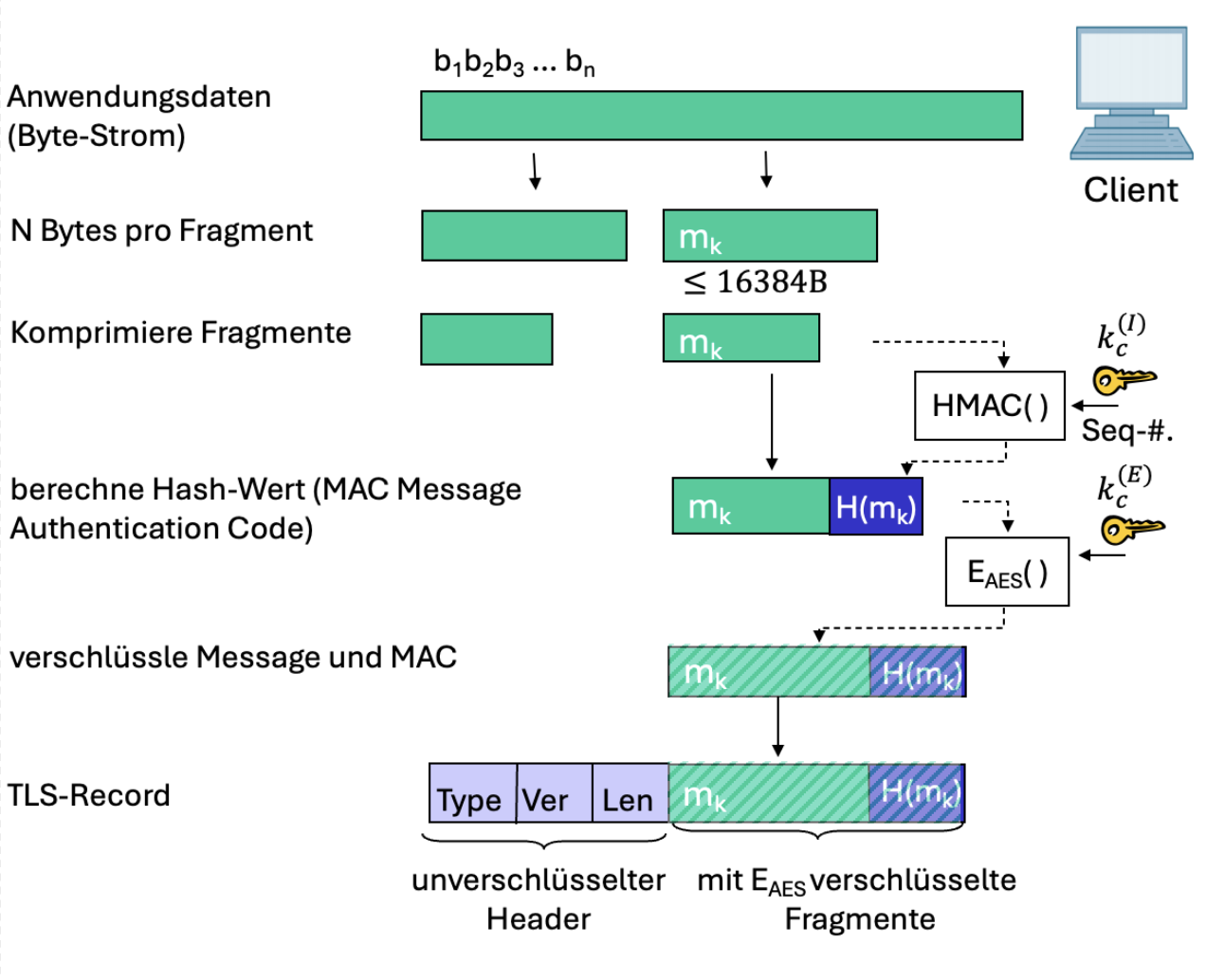
- *Fragmentierung: Byte-Strom wird in TLS-Fragmente aufgeteilt. Max. Fragmentgröße: B
- Datenkomprimierung (optional): Fragmente können komprimiert werden
- Message Authentification Code (MAC): 16 Byte langer Code zur Sicherstellung von Integrität und Authentizität der transportierten Daten
- Wird mit Hash-Funktion generiert und mit einem Schlüssel pro Fragment berechnet:
- Wird an Nachricht angehängt
- Datenverschlüsselung: Verschlüsselt die Kombination aus und mittels symmetrischem Verschlüsselungsverfahren unter Verwendung eines Verschlüsselungsschlüssels
- Header: 5 Byte lang. Enthält den Content-Type, die TLS-Version und Länge des Payloads.
DNS Hosts und Netzwerkgeräte können über Hostnamen und IP-Adressen eindeutig adressiert werden. Der Domain Name Service (DNS) ist ein weltweiter Dienst zur Namens- und Adressauflösung in großen Netzwerken. Auflösung bei DNS bedeutet Zuordnung: Hostname → IP-Adresse: Lookup, IP-Adresse → Hostname: Reverse Lookup. DNS ist ein Protokoll der Anwendungsschicht, wird also von Applikationen verwendet.
DNS-Namen
- Fully Qualified Domain Name (FQDN)
- Eindeutiger Hostname
- Punkt am Ende wird meist weggelassen
- DNS-Namen dürfen nur Buchstaben, Zahlen, Bindestriche und Punkte enthalten
- DNS-Namen sind case-insensitive
- Punkte dienen zum Trennen der Labels (TLD, Domain, Subdomain, Hostname)
- Jedes Label darf max. 63 Zeichen lang sein
- FQDN darf max. 255 Zeichen lang sein
- Durch DNS können für eine IP-Adresse mehrere Namen vergeben werden
- A-Einträge definieren die Primäre IP-Adresse
- CNAMEs sind Aliasnamen
- AAAA-Einträge sind wie A-Einträge, aber für IPv6
- Es können mehrere IP-Adressen einem kanonischem Namen zugewiesen werden → Load Balancing
DNS-Datenbank
- DNS wird in Form einer weltweiten verteilten Datenbank zur Verfügung gestellt
- Die verteilten Datenbanken werden durch DNS-Server bereit gestellt
- DNS-Hierarchie besteht aus 3 Ebenen → schnelle Namensauflösung
Root-Nameserver
- DNS ist der zentrale Dienst im Internet → Ohne DNS funktioniert das Internet nicht!
- DNSSEC wird zur Absicherung der Einträge der Datenbank verwendet
- Einträge werden mit digitalen Zertifikaten signiert
- ICANN verwaltet die DNS Root Domain
- Die Root-Domain besteht aus 13 logischen Root-Servern
- Pro Root-Server existieren weltweit physikalisch verteilte DNS-Server
- Mittels Anycast (eine Adresse für mehrere Server, Client fragt Server an, zu dem kürzeste Route ist) erfolgt eine Lastverteilung der DNS-Anfragen über die Server
- Ein Root-Nameserver wird von einem Top-Level-Nameserver kontaktiert, wenn dieser einen Namen nicht auflösen kann
- Kennt die Adressen aller TLDs (com, net, org, gg, de, uk, …)
- Es gibt 13 logische Root-Nameserver, die nach dem Schema
[a-m].root-servers.netbenannt sind
TLD-Server
- Verantwortlich für jeweils eine TLD
- com, org, net, edu, … oder de, uk, fr, ca, jp, …
- Die Verwaltungsstelle einer TLD ist für alle Domainnamen innerhalb ihres Namespaces zuständig
- Für Länderbezogene TLDs ist das jeweilige Land verantwortlich
Autorativer DNS-Server (Autoritative DNS Server)
- DNS-Server einer Organisation, der eine autorisierte Abbildung der Namen dieser Organisation auf IP-Adressen anbietet und diese im Internet bereitstellt.
- Verwaltet von Organisation selbst oder Service Provider
Iterative Namensauflösung
- Host
example.comfragt nach der IP-Adresse von Host lou.gg bei Default DNS-Serverdns.example.coman. - Lokaler DNS-Server fragt DNS-TLD-Server nach IP-Adresse für TLD-Server für
.ggan - Default DNS-Server fragt danach den
.gg-TLD-Server nach IP-Adresse des autoritativen DNS-Servers fürlou.gg - Default DNS-Server fragt autoritativen DNS-Server nach IP-Adresse für
lou.ggund erhält diese
Zeitbedarf für 4 DNS-Anfragen & -Antworten:
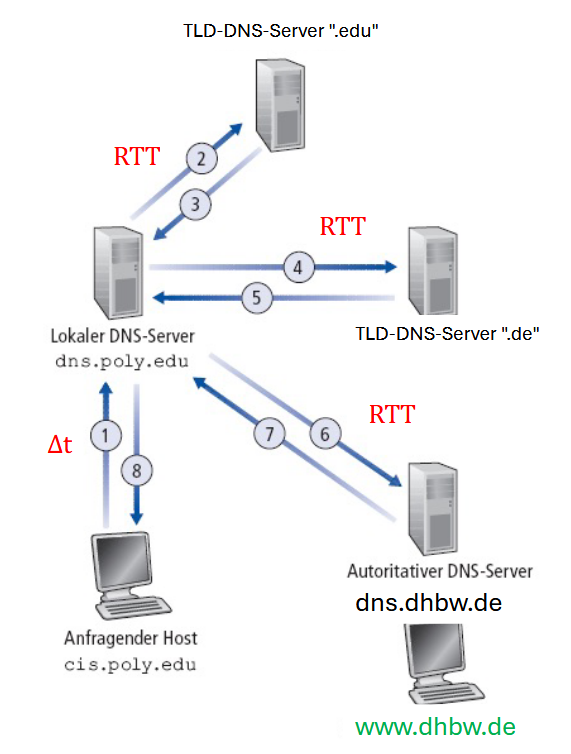
- Sobald ein lokaler/default Nameserver von einer erfolgreiche Namensauflösung erfährt, kann er den Eintrag cachen
- Cache hat eine TTL, die pro DNS-Record festgelegt werden kann. Typisch sind 900 Sekunden.
- Jeder Nameserver und auch lokale Geräte cachen DNS-Records. Anfragezeit für jedes Level an Caching:
- Endgerät kennt IP: 0 Sekunden
- Default Nameserver kennt IP: -2 RTT
Transportprotokolle im Internet
- TCP (Transport Control Protocol): Applikationsorientierter, zuverlässiger End-to-End Bytestream
- Verbindungsaufbau: Vollständig, mit richtiger Reihenfolge
- Flusskontrolle: Keine Überlastung des Empfängers
- Überlastkontrolle: Keine Überlastung des Netzwerks
- Multiplexing: Verteilung der Segmente zwischen den Prozessen
- Fehlerüberprüfung des Segments
- UDP (User Datagramm Protocol): Best-Effort-Transport
- Multiplexing: Verteilung der Datagramme zwischen den Prozessen
- *Fehlerüberprüfung des Datagramms
- Dienste, die beiden Protokollen nicht zur Verfügung stehen:
- Garantien bezüglich Bandbreite, Latenz, Echtheit, Verschlüsselung
Multiplexing beim Sender
- Mehrere Anwendungen kommunizieren auf einem PC über das Netzwerk, benötigen also mehrere Sockets
- Nachrichten von den verschiedenen Sockets werden in der Transportschicht je nach Größe in Segmente/Datagramme aufgeteilt, die zusätzlich einen Header H erhalten, der die Quell- und Zielportnummer der Anwendung spezifiziert
- Segmente/Datagramme werden via Multiplexing an die Vermittlungsschicht übergeben und erhalten dort einen Header , der Quell- und Ziel-IP-Adresse der Endgeräte enthält
Demultiplexing beim Empfänger
- Endgerät empfängt IP-Packets
- Jedes Packet hat im Header eine Absender-IP-Adresse und eine Empfänger-IP-Adresse, ein TCP-Segment oder ein UDP-Datagramm und einen Absender-/Empfänger Port
- Hosts nutzen IP-Adressen und Portnummern werden genutzt um die Segmente/Datagramme an den richtigen Socket weiterzuleiten
TCP: Grundlagen der zuverlässigen Datenübertragung
- Zuverlässiger Datentransfer bedeutet:
- Fehlerfreie Übertragung der Bits
- Reihenfolge der Bits bleibt erhalten
- Alle Packets werden vollständig übertragen
- Kann in mehreren Schichten implementiert werden: Anwendungsschicht, Transportschicht und Sicherungsschicht
- Jeweilige Protokollschicht implementiert die zuverlässige Übertragung als Dienst
- Die darüberliegenden Netzwerkschichten können die Datenübertragung als Dienst konsumieren
- Beispiel: HTTP/2 an sich ist unzuverlässig, da es aber TLS & TCP nutzt wird es zuverlässig
Überblick TCP
- TCP (Transmission Control Protocol) ist ein Punkt-zu-Punkt Protokoll: ein Sender, ein Empfänger.
- TCP ist verbindungsorientiert: ein 3-Way-Handshake initialisiert einen Sende- und Empfangszustand im Sender und Empfänger, bevor Daten ausgetauscht werden
- Es gibt Sende- und Empfangspuffer
- Sendepuffer: Daten von Applikationsschicht werden gesammelt und segmentweise an die Vermittlungsschicht weitergegeben.
- Empfangspuffer: Speichert empfangene Segmente. Transportschicht stellt Daten aus Puffer byteweise der Anwendungsschicht zur Verfügung.
- Bei TCP fließen Daten in beide Richtungen (jede Seite besitzt Sende- und Empfangspuffer)
- TCP teilt den Bytestrom der Anwendungsschicht in Segmente auf
- Segmente werden durch eine Sequenznummer identifiziert
- Nach Empfang mehrerer Segmente bestätigt Empfänger dies mit einer ACK-Nachricht
- Pipelining: Bei TCP können mehrere Segmente gleichzeitig über eine Verbindung gesendet werden
- Anzahl der Packets ist die TCP Window Size
- Flow Control:
- Empfänger steuert Datenfluss des Senders mit der freien Kapazität des Empfangspuffers
- Empfänger übermittelt dazu die Größe des Empfangspuffers mit dem “Receive Window”
- Congestion Control:
- Netzwerk teilt überlast mit, TCP regelt dynamisch die Maximalzahl an gleichzeitig sendbaren Packets: “Congestion Window”
TCP Segment-Aufbau
- TCP Header ist 20 Byte lang und kann mittels Optionen erweitert werden. Optionen dürfen max. 40 Byte lang sein.
- Sequence Number: 4 Byte groß. Enthält eine zufällig generierte Nummer, die bei Initialisierung der Verbindung entschieden wird. Ist während der Datenübertragung für die Sortierung und Fehlererkennung zuständig.
- Acknowledgement Number: 4 Byte groß. Gibt die Sequence Number an, die der Empfänger als nächstes erwartet. Nur gültig bei ACK-Flag .
- HLEN (Header Length): Gibt die Länge des TCP-Headers in 4 Byte-Blöcken an. (Standard-Länge: 5 → )
- Window Size: Gibt Anzahl der freien Bytes im Empfangspuffer des Senders an
- Urgent Pointer: Wenn URG-Flag gesetzt ist zeigt dieser Wert das Ende der Urgent-Daten im Payload an, welche sofort nach dem Header beginnen.
- PSH-Flag: Wenn gesetzt soll der TCP-Stack die empfangenen Daten sofort an die Anwendungsschicht weitergeben, ohne zu warten. Wird häufig bei Echtzeit-Applikationen verwendet.
Three Way Handshake beim TCP-Verbindungsaufbau
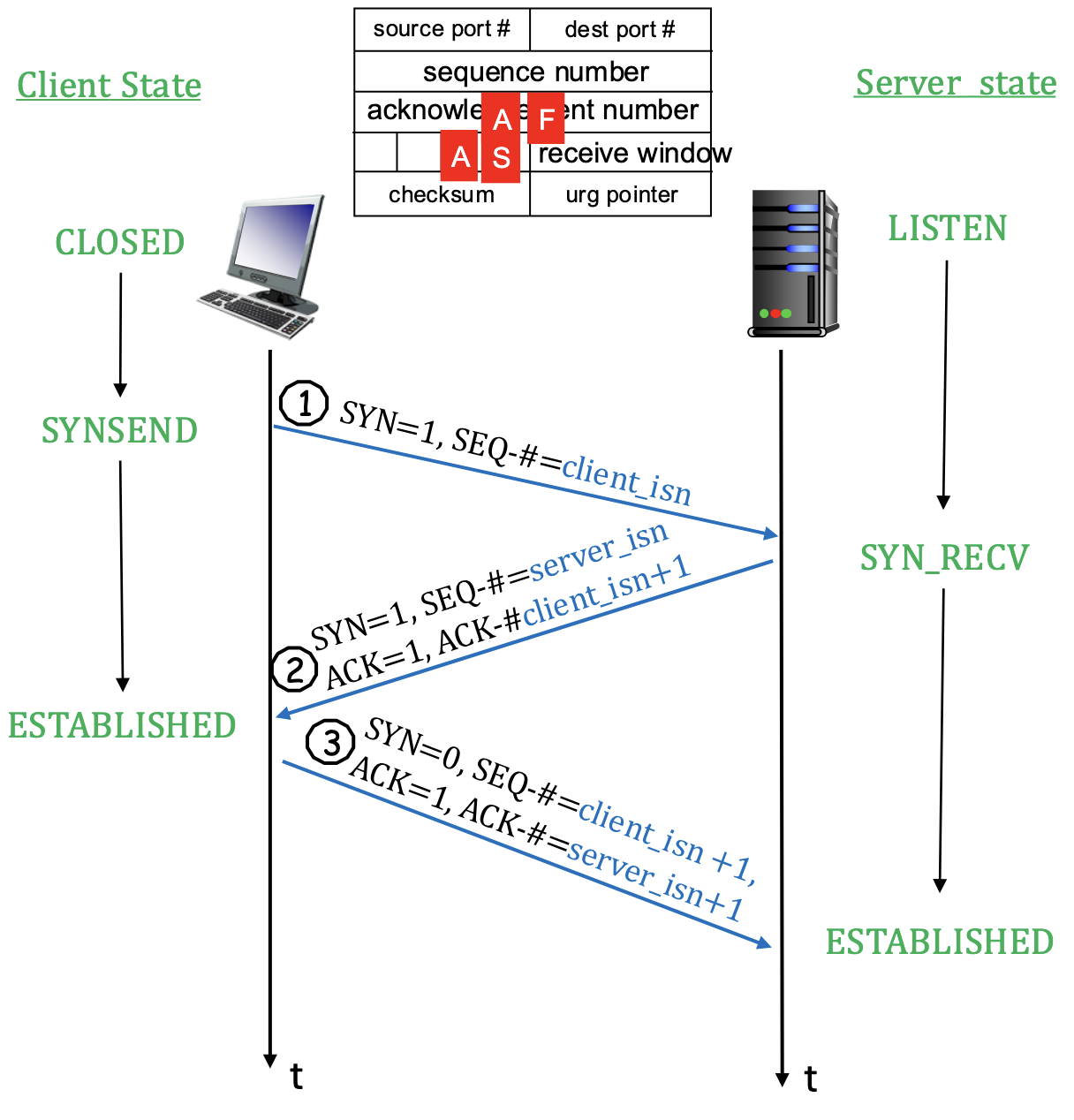
- TCP Sender und Empfänger bauen eine Verbindung auf, bevor sie Daten austauschen können
- Schritt 1: SYN-Packet
- Client sender ein SYN-Segment (SYN-Flag = 1, ACK-Flag = 0) an Server
- Übermittelt zufällig ausgewählte initiale Client-ISN im Sequenznummernfeld.
- Übermittelt keine Daten.
- Schritt 2: SYNACK-Packet
- Server empfängt SYN und antwortet mit SYNACK-Segment (SYN = 1, ACK = 1)
- Übermittelt initiale Sequenznummer Server-ISN und Acknowledgement-Nummer Client-ISN + 1 zur Bestätigung der Anfrage
- Es werden keine Daten übermittelt
- Schritt 3: ACK-Packet
- Client empfängt SYNACK-Packet und antwortet mit ACK-Packet (SYN = 0, ACK = 1)
- Client bereitet Empfangspuffer für die Verbindung vor (alloc)
- Client übermittelt Acknowledgement-Nummer für den Server: Server-ISN + 1
- Client darf Daten mitschicken
- Schritt 1: SYN-Packet
Schließen einer TCP-Verbindung
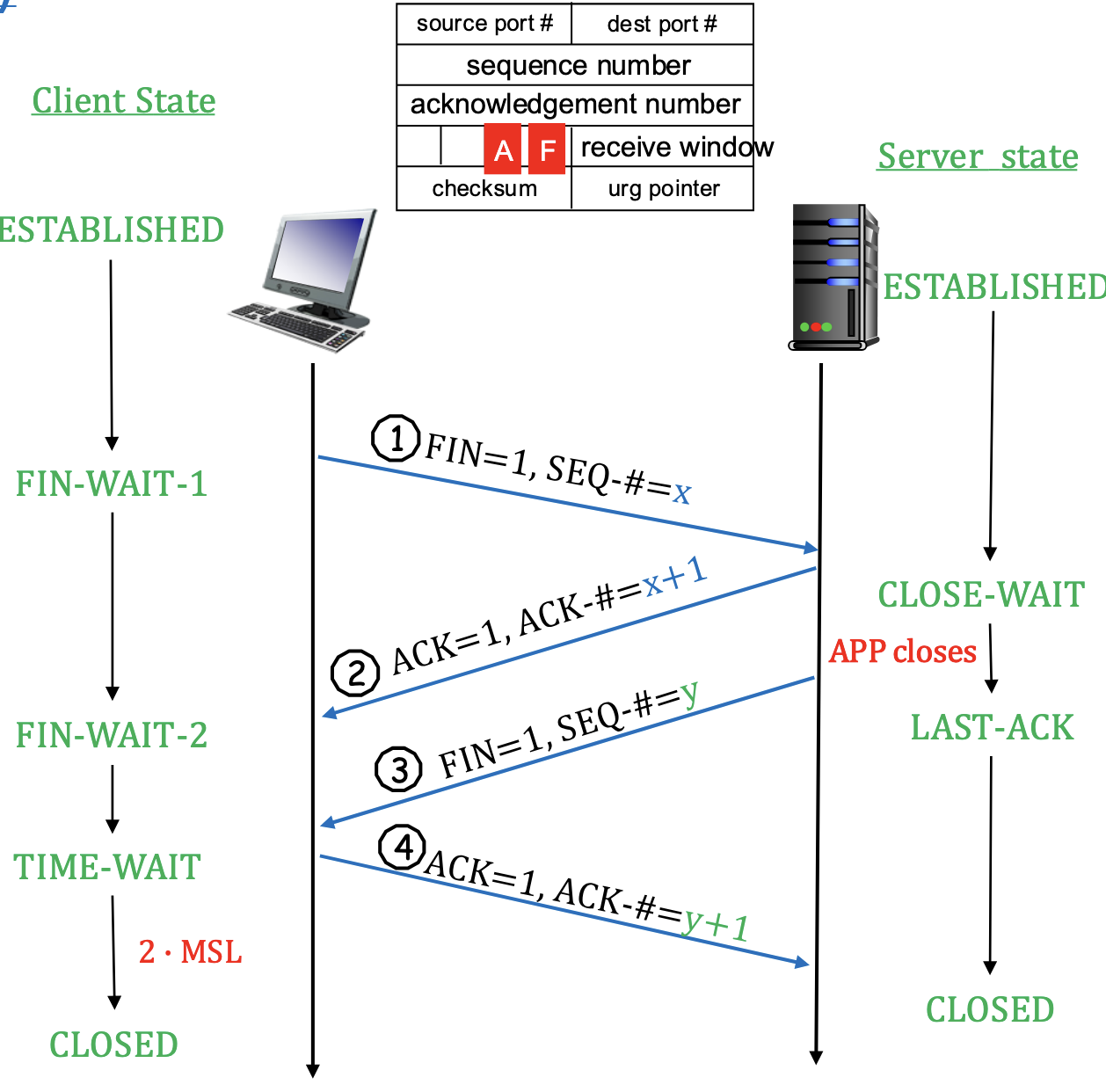
- Verbindung kann von beiden Seiten geschlossen werden
- Nach schließen der Verbindung werden die reservierten Ressourcen in den Systemen freigegeben
- Schritt 1: Client sendet ein FIN-Segment (FIN-Bit = 1) an den Server. Segment enthält die Sequenz-ID für das nächste mögliche Byte
- Client wechselt in Zustand FIN-Wait-1
- Schritt 2: Server empfängt FIN und antwortet mit ACK-Segment. Sequenz-ID wird um 1 erhöht
- Client empfängt ACK-Segment und Wechselt in FIN-Wait-2
- Server wechselt in Close Wait und wartet auf Close-Anweisung der Applikation
- Schritt 3: Server sendet nach Erhalt der Close-Anweisung ein TCP-FIN-Segment (FIN = 1) an den Client.
- Segment enthält Segment-ID für das nächste mögliche Byte
- Server wechselt in LAST-ACK
- Schritt 4: Client empfängt FIN-Segment, Antwortet mit LAST-ACK-Segment mit Sequenz-ID
- Client wechselt in Time Wait, wartet auf FIN-Sendewiederholungen des Servers (falls LAST-ACK nicht angenommen wurde), die er mit neuen ACK-Segmenten beantwortet
- Nach Wartezeit von (Max. Segment Lifetime) schließt der Client die TCP-Verbindung, geht in Closed-Zustand über und gibt alle reservierten Ressourcen frei
- Server empfängt ACK-Segment, schließt TCP-Verbindung, wechselt in Closed-Zustand und gibt Ressourcen frei
- Schritt 1: Client sendet ein FIN-Segment (FIN-Bit = 1) an den Server. Segment enthält die Sequenz-ID für das nächste mögliche Byte
TCP: Sequenznummern und ACK-Nummern
- Die Sequenznummern (Seq-#) dienen zur Nummerierung der Segmente
- Anfangssequenznummer (Initial Sequence Number, ISN) wird zufällig gewählt
- TCP Handshake addiert 1 dazu
- Sequenznummer für initiale Datenübertragung startet also bei ISN + 1
- Acknowledge (ACK): Bestätigung des fehlerfreien Empfangs eines Segments
- ACK-# ist Sequenznummer des nächsten erwarteten Bytes im Byte-Strom der sendenden Applikation
TCP: Verlust eines ACK-Packets
- Wenn Sender kein ACK-Packet für ein Segment erhält, weiß er nicht, ob das Packet richtig angekommen ist.
- Lösung: TCP startet Timer für ältestes noch nicht bestätigtes Segment
- Neuübermittlung für ältestes Segment, wenn Timer überschritten wird
- Max. Anzahl an Neuübermittlungen ist konfigurierbar
TCP Flow Control: Empfangspuffer Unter Flow Control versteht man die Anpassung der Senderate an die Verarbeitungsrate der Anwendung des Empfängers.
- Empfänger speichert eingegangene Daten im Empfangspuffer und bestätigt diese mit einem ACK
- Anwendungsprozess extrahiert Daten aus Empfangspuffer
- Empfangspuffer hat Größe “RcvBuffer”
- Je nach Auslastung des Hosts/Anwendung kann es zu Verzögerungen bei der Abarbeitung des Eingangspuffers kommen
- Empfänger übermittelt die Größe seines freien Pufferspeichers RcvWindow in Bytes mit jedem ACK-Packet im TCP-Header-Feld “Receive Window” (Empfangsfenster)
- Receive Window: 16 Bit-Feld → Max. 65kB an Daten pro RTT übermittelbar
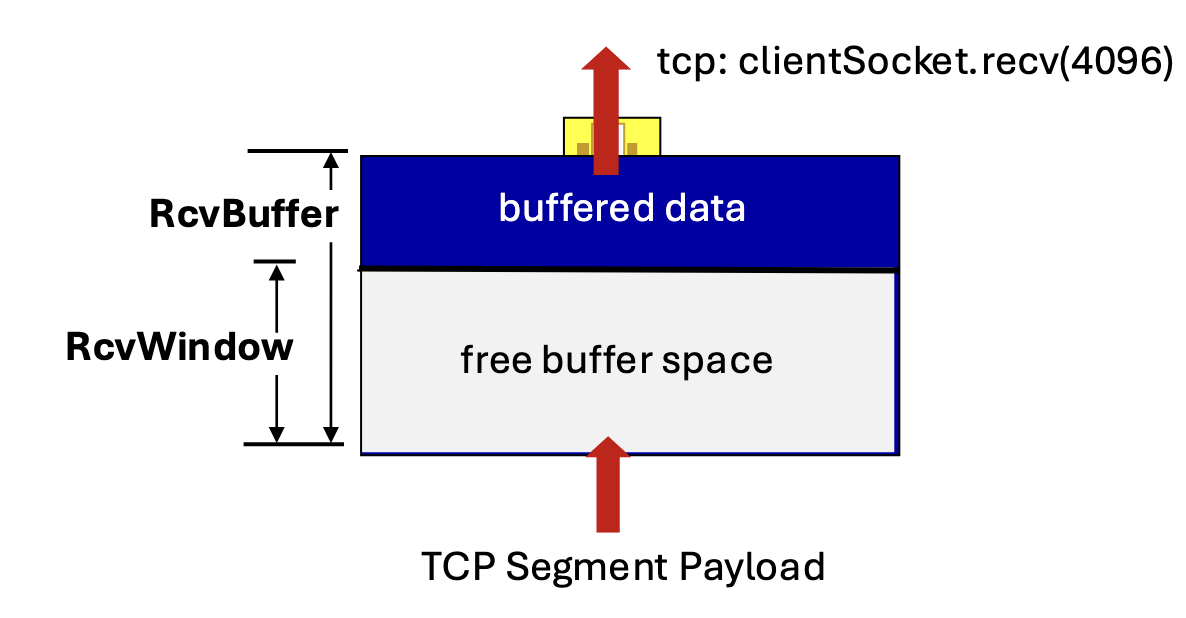
TCP Flow Control: RcvWindows
- Sender liest die aktuelle Größe des Empfangsfensters RcvWindow und passt die Anzahl rwnd der Segmente, die gesendet werden können wie folgt an: , wobei = max. Payload-Größe eines Segmentes ist
- Ist der Eingangspuffer des Empfängers vollgelaufen (RcvWindow = 0) kann der Sender keine Daten mehr schicken.
- TCP Zero Window Probes: Damit der Sender einen neuen Status über die Größe des Eingangspuffers vom Empfänger erhält, sendet der Sender weiter TCP-Segmente ohne Payload.
TCP: Flow Control
- Max. Größe des Receive Windows: 16 Bit
- Zeitdauer, um ein TCP-Segment der Größe auf einer Verbindung mit Hops und näherungsweise konstanter Bandbreite erfolgreich zu übertragen ist gegeben durch
- Bei einem RcvWindow zum Zeitpunkt werden Segmente übertragen. Die Datenübertragungsrate ergibt sich zu:
(Typische Werte: )
TCP Flow Control: Window Scale Option
- Originale TCP Header für alte Geräte/Leitungen gemacht, nicht für heutige Geschwindigkeiten
- TCP kann schlecht geändert werden, da weltweit verwendet
- TCP kann durch optionalen Header-Bereich erweitert werden
- Header-Option besteht aus: Type - Length - Value (TLV)
- Type (1 Byte): Nummer, die TCP-Option beschreibt (max. 256 Optionen)
- Length (1 Byte): Länge der Option in Byte
- Value: Wert der Option
TCP Congestion Control: Überlastkontrolle des Netzwerkes
- Wenn alle Sender so viele Packets schicken, wie in den Puffer der Empfangsseite passen, kann es an Kreuzpunkten eines Netzwerkes zur Überlastung der Netzwerkgeräte kommen.
- Es kann zu steigenden Wartezeiten in der Queue eines Routers kommen → Pufferüberlauf, packet loss
- Beim Sender treten Timeouts auf, verbunden mit erneuter Übertragung von bestimmten Packets
- Überlastung eines einzelnen Routers kann auch zur Überlastung mehrerer Router führen, da TCP auf bestimmte Packets keine Antwort erhält und erneut Packets sendet → Andere Router-Queues werden ebenfalls überfüllt
- Domino-Effekt kann zu Kollaps des Netzwerkes führen
⇒ Lösung: Congestion Control (Überlastkontrolle)
- Es gibt zwei Arten von Überlastkontrolle:
- TCP Congestion Control
- TCP/IP Netzwerkunterstützte Congestion Control
TCP Congestion Control: Netzwerkunterstützte Congestion Control
- Router versuchen eventuelle Überlast durch Algorithmen wie Weighted Random Early Detection (WRED) vorzeitig zu prognostizieren
- Entweder verwerfen Netzknoten gezielt und frühzeitig einzelne Packets, um Überlast anzuzaugen, oder sie signalisieren dem Empfänger durch senden eines CE-Bits im IP-Header explizit den Überlastzustand
- Empfänger informiert Sender über das ECE-Bit im TCP-Header
TCP Congestion Control: Explicit Congestion Notification (ECN)
- Das Feld ECN besteht aus 2 Bits und befindet sich im IP-Headers-Field “Type of Service”.
- ECN besteht aus ECT und CE Bits
- Sender: Das ECT-Bit im IP-Header wird auf 1 gesetzt, wenn der Sender ECN unterstützt
- Router: Das CE-Bit im IP Header wird im Falle der Überlastung eines Routers von diesem auf ! gesetzt.
TCP Congestion Control: Explicit Congestion Notification Echo (ECE)
- Empfänger: Der Empfänger setzt im Falle von CE = 1 das ECE-Bit im TCP-Header auf 1 und versendet die zugehörige ACK-Nachricht an den Sender.
- Sender: Der Sender erkennt Congestion und reduziert Sendefenster wie bei Packetloss und informiert den Empfänger durch das setzen der CWR-Flag (Congestion Window Reduced) im nächsten Segment
TCP Congestion Control: Netzwerkunterstützte Congestion Control
- ECT muss auf hosts explizit aktiviert werden (ECT = 1 im IP Header)
- Wenn Netzwerk nicht belastet ist: ECN = ECH & CE = 10
- Wenn Netzwerk überlastet ist: ECN = 11
- Empfänger erkennt Überlast im IP-Header und setzt die ECE-Flag im nächsten ACK-Segment auf 1
- Sender erhält ACK Segment, erkennt Congestion und reduziert Fenstergröße
- Empfänger sieht CWR und beendet das Setzen des ECE-Bits auf 1
TCP Congestion Control: Congestion Window
- Ziel: Bestimmung der optimalen Senderate als Funktion der Netzlast.
- Erkennung
- Sender:
- Ablauf von RTO-Timer → Annahme: Verlust vieler Segmente
- Duplicate ACKs → Annahme des Verlustes einzelner Segmente
- Empfänger:
- Einführung von Congestion Window analog zur Flow Control:
- Zusätzliche TCP-Variable für Sender
- Beschränkt die Anzahl an unbestätigten Segmenten, die der Sender senden darf
- Congestion Control und Flow Control sind im Sender gekoppelt
- Anzahl max. unbestätigter Segmente in der Pipeline wird durch Minimum aus und bestimmt:
- Einführung von Congestion Window analog zur Flow Control:
- Sender:
TCP Congestion Control: Senderate und Congestion Window
- Effektives Fenster bestimmt Senderate des Senders
- Kann analog zur Senderate bei der Flusskontrolle abgeschätzt werden:
- Am Anfang eines RTTs darf der Sender mit Datenbytes senden
- Nach RTT:
- Neue ACKs erhalten: Mehr oder weniger “Sendeplätze” werden frei gegeben
- Fehlende ACKs bemerkt: Reduktion der “Sendeplätze”
- Senderate D pro RTT:
TCP Congestion Control: Steuerung des Congestion Windows: AIMD *AIMD: Additive Increase Multiplicative Decrease
- Erhöhe die Fenstergröße um 1 pro RTT, bis Überlast erkannt wird
- Halbiere , sobald Überlast erkannt wird
⇒ Sägezahn-Verlauf
TCP Congestion Control: Slow Start für Congestion Window
- Mit erstem Datenversand oder nach Segmentverlust startet das TCP Slow Start-Verfahren mit einem Congestion Window der Größe 1 ()
- Bei Fehlerfreiheit aller gesendeten Segmente wird das Congestion Window innerhalb eines RTTs verdoppelt:
- Slow Start endet, wenn einen Threshold erreicht (default: 8)


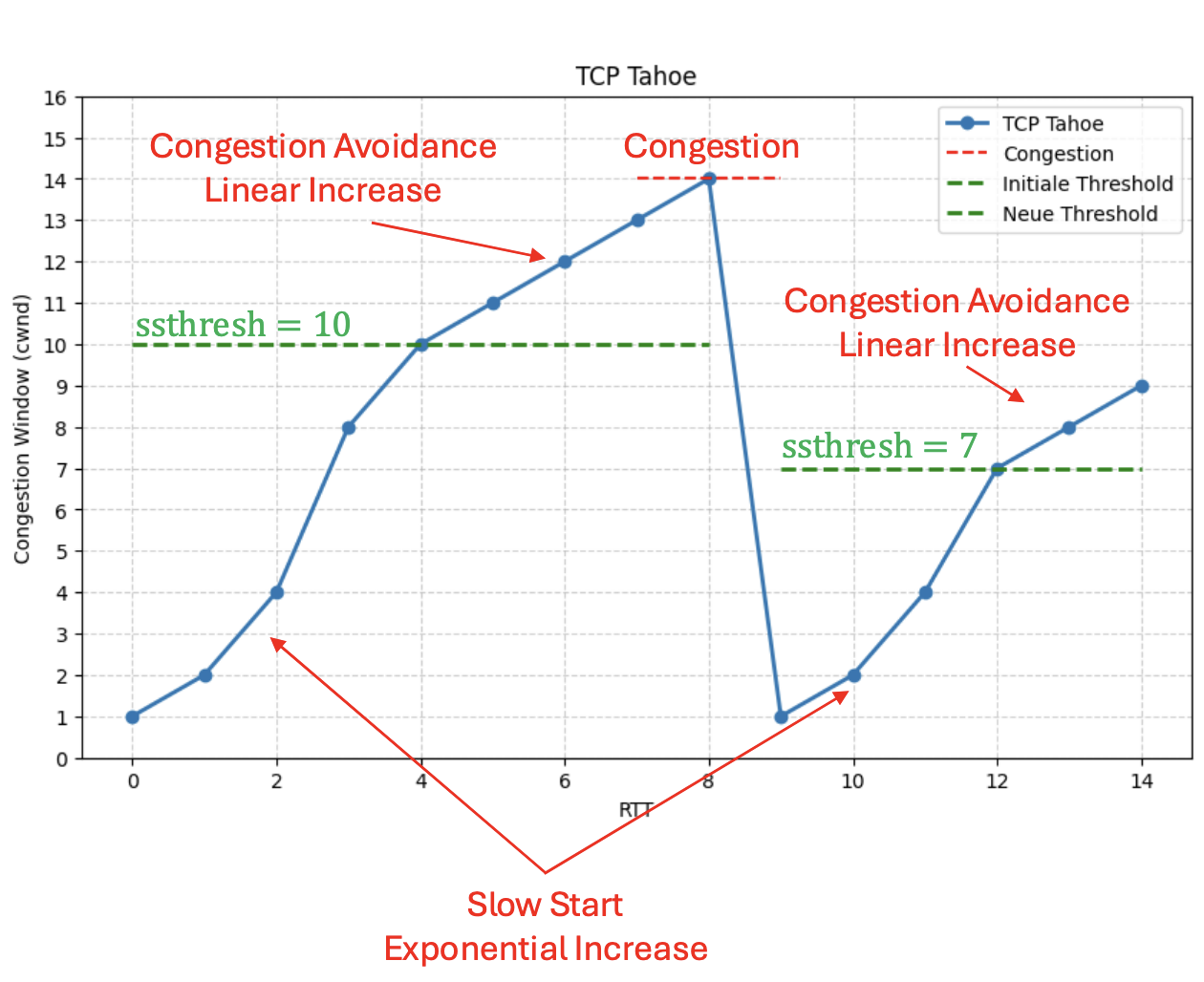
TCP Tahoe
- Verbesserung: Nach erkannter Congestion wird der Threshold auf gesetzt, wobei der letzte maximale Wert vor Congestion ist. wird auf 1 gesetzt.
TCP Reno
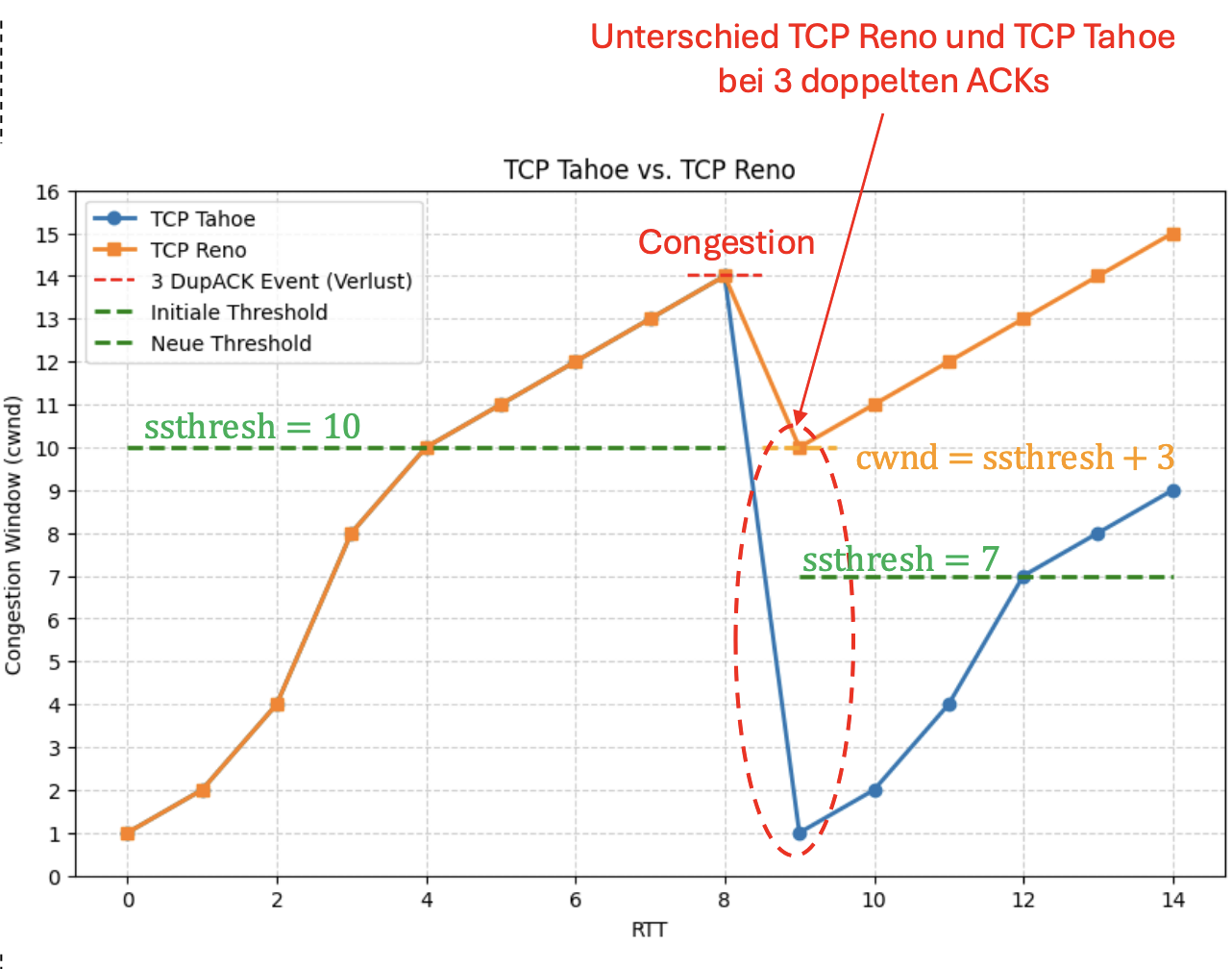
- Verbesserung: Zwei Fälle
- Fall 1: RTO-Timeout
- Verhalten wie bei TCP Tahoe. , Slow Start.
- Fall 2: 3 doppelte ACKs
- Vermutung: Einzelsegmentfehler, Netzwerk funktioniert noch
- Fast Retransmit des fehlenden Packets und Übergang in “Fast Recovery”-Modus
- Fast Recovery-Modus:
Die Netzwerkschicht
- Die Netzwerkschicht (Network Layer) transportiert die Segmente der Transportschicht vom Sender zum Empfänger
- Sender verpackt Segmente der Transportschicht in IP Packets, übergibt diese der Sicherungsschicht
- Empfänger entpackt das empfangene Packet und übergibt das Segment der Transportschicht
- Router liest Header eines IP Packets und leitet das Packet auf Basis seiner Header-Information von einem Eingangsinterface zu einem Ausgangsinterface mit dem Ziel, das Packet entlang eines möglichst schnellen Ende-zu-Ende-Pfades durch das Internet zu führen
- Protokoll der Vermittlungsschicht ist in jedem Internet-Gerät implementiert (Host, Router)
Datenebene und Kontrollebene
- Kontrollebene:
- Netzwerkweite Logik: Routing
- Bestimmt auf welcher Route ein Daten
- Datenebene:
- Lokale Logik pro Router: Forwarding
- Bestimmt zu welcher Ausgangsleitung ein eingehendes Datagramm weitergeleitet wird
Dienstmodell der Netzwerk
- Internet agiert mit “Best Effort” Service Modell. Es gibt keine Garantien auf:
- Loss: Erfolgreiche Zustellung
- Order: Reihenfolge der Daten
- Timing: Zeitliche Verzögerungen
- Bandwidth: Verfügbare Bandbreite
- Es gibt ein erweitertes Modell:
- Integrated Services: Ende-zu-Ende Reservierungen (Leitungsvermittlung)
- Differentiated Services: Markierung einzelner Packets mit Qualitätsklassen
4.2 IPv4 & IPv6
- Das Internet Protocol hat die Aufgabe, Netzwerkteilnehmer mit einer eindeutigen Adresse zu versorgen und Packets an die richtige Adresse weiterzuleiten.
- Es gibt zwei Versionen, die bei allen Internet-Teilnehmern implementiert sind.
- IP verwendet folgende Protokolle des Control Plane:
- Routing: OSPF, BGP
- Status: ICMP
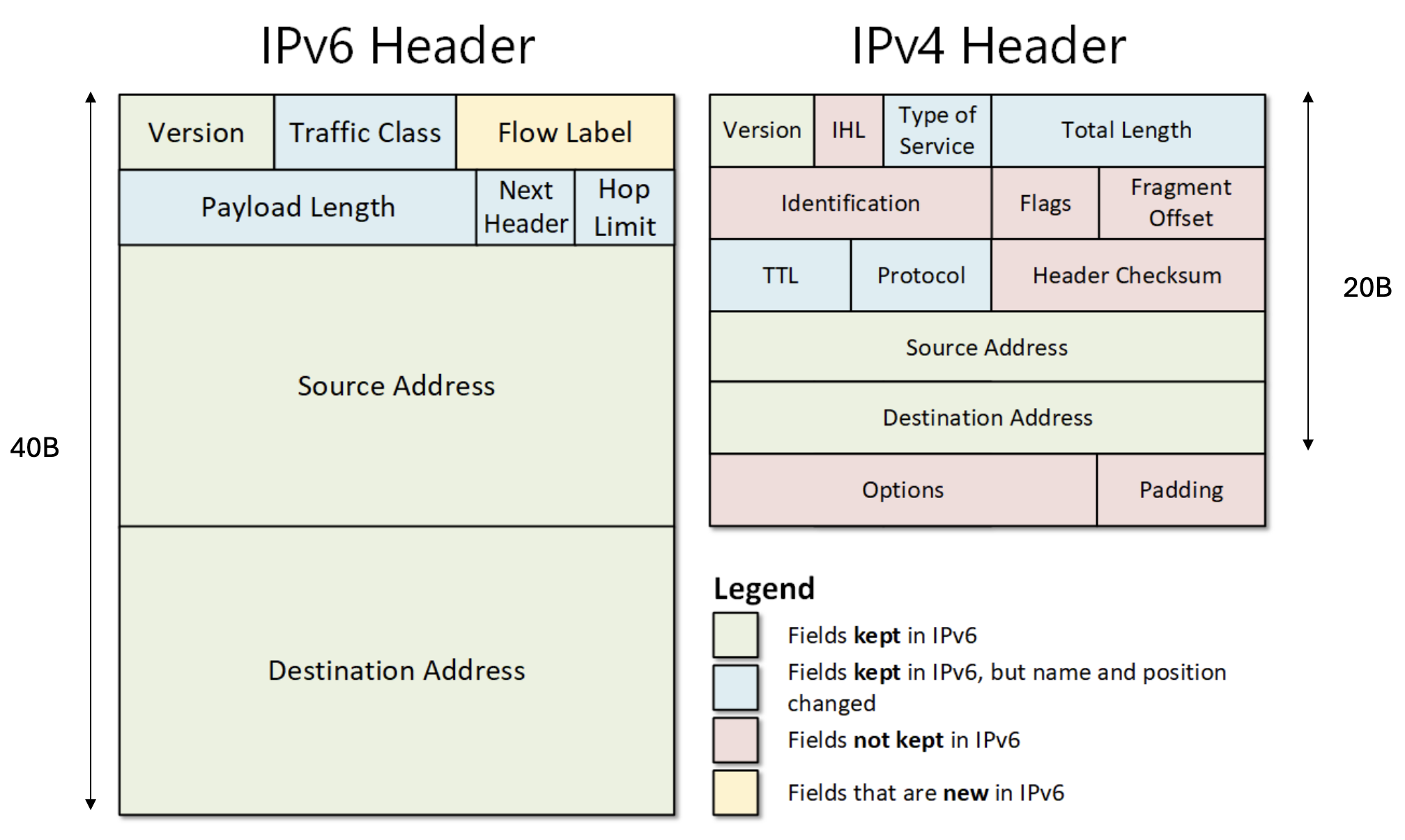
IPv4 Packet Format
- IPv4 Header: 20 Byte
- Version (4Bit): IPv4 Version “0100” → 4
- Internet Header Length IHL (4Bit): Zahl 5, gibt die Länge des IP Headers in 4B-Einheiten an (analog zu TCP Header Length)
- Min. Länge: 5 4B = 20B
- Max. Länge: 15 4B = 60B
- Type of Service TOS (8Bit):
- DSCP (0:5): Differentiated Services Code Point (6Bit)
- ECN (6:7): Explicit Congestion Notification (2Bit)
- Time-To-Live (8Bit): Wert in Sekunden (max. 255), jeder Hop reduziert Wert um 1, Packets mit TTL = 0 werden gelöscht und nicht weitergeleitet
- Upper Layer Protocol (8Bit): Von der ICANN definierte Nummern
- 1: ICMP
- 6: TCP
- 17: UDP
- 89: OSPF
- Header Checksum (16Bit): Internet Checksum für IP Header
- Source & Destination IP Address (32Bit each)
- Header Options (4Bit): Angabe in Vielfachen von 4B (32Bit)
- Besteht aus Vielfachen von TLV-Optionen (Record Routes, Source Routes)
- ggf. Padding, um vielfaches von 32Bit zu erreichen
IP Packet Fragmentation
- Max. Größe eines Packets: 65535B
- Layer-2-Protokolle limitieren Packet Size
- Ethernet: MTU = 1500 Byte
- WLAN: MTU = 2312 Byte
- ⇒ MTU: Maximum Transfer Unit, gibt max. Größe für IP Packet an.
- Wenn die MTU einer Leitung sinkt, muss unter Umständen das Packet vom Router fragmentiert werden, um die Leitung nicht zu blockieren
- Jedes Fragment wird durch eine zufällig generierte Fragment-ID (16Bit) identifiziert
- Fragment-ID wird vom Sender auch gesetzt, wenn keine Fragmentierung statt findet
- Fragment Flags:
- Erstes Bit: Immer 0
- Zweites Bit: DF-Flag (Don’t Fragment)
- DF = 0 → Fragmentierbar
- DF = 1 → Nicht Fragmentierbar
- Drittes Bit: MF-Flag (More Fragment)
- MF = 0 → Letztes Fragment
- MF = 1 → Es kommen weitere Fragmente
- 13 Bit Fragment Offset: Offset als Vielfaches von 8 Bytes in Bezug zu Anfang des Original-Packets (Offset zeigt quasi die Nummer des Packets)
Minimale MTU
- IPv4: 576B
- IPv6: 1280B
- Fragmentierung tritt erst oberhalb dieser Werte ein
IPv6 Packet Format
- Version (4Bit): “0110” → 6
- IP-Adressen (je 128B): Tupel aus 16B langen Adressen
(Source-IP, Destination-IP) - Flow-Label (20Bit):
- Traffic Class (8Bit): Analog zum Type of Service Feld in IPv4
- Flow-Label (20Bit): Eindeutige ID, um Packets zwischen gleichem Sender und Empfänger zu kennzeichnen
- Payload length (16Bit): Länge des Payloads
- Next Header (8Bit): Nächster Header oder Upper Protocol
- Hop Limit (8Bit): Anzahl max. Hops bis zum Erreichen des Empfängers, entspricht IPv4 TTL
IPv6 Flow Labels
- Ziel: Quality of Service-Steuerung von IPv6-Packets
- Flow Label dient der Identifizierung von Daten-Packets einer Anwendungssitzung zwischen gleichem Server und Client auf allen Routern
- Router sind dann in der Lage auf alle Packets dieser Verbindung eine Dienstgüte anzuwenden
- Integrated Services: Sender kann mittels Resource Reservation Protocol (RSVP) Dienstgütegarantien pro Flow Label anfordern
- Feste Bandbreiten
- Max. Verzögerungszeit pro Packet
- Kein Packet Loss bei Überlast
IPv6 Next Header
- Bietet die Möglichkeit, den fixen Header um weitere Header zu ergänzen, die optionale Informationen tragen (Routing-Header, Fragment-Header, …)
- Next-Header-Feld kennzeichnet entweder den ersten Extension-Header (falls vorhanden) oder das Protokoll des nächsten Layers (TCP, UDP)
IPv6 Fragmentation Header
- Fragmentierung in IPv6 wird exklusiv von der Quelle durchgeführt, die Router führen keine Fragmentierung durch.
- Wenn ein IPv6-Packet zu groß für den nächsten Router ist, generiert dieser ein ICMP-Packet, um die Quelle darüber zu informieren. Die Quelle muss dann das Packet fragmentieren.
- Fragmentation Header besteht aus:
- Next Header (8Bit): Identifiziert den Header-Typ, der nach dem Fragmentation Header vorhanden ist
- Reserved (8Bit): Immer 00000000
- Fragment-Offset (13Bit): Analog zu IPv4, Vielfaches von 8B in Bezug zum Anfang
- More Fragment M (1Bit): Analog zu IPv4
- Identification (32Bit): Analog zu IPv4, allerdings mit doppelter Größe.
IPv4 vs IPv6 Header
Grundlagen der IP-Adressierung
- Eine IP-Adresse ist die Adresse eines Interfaces eines Endsystems oder Netzwerkgerätes
- Interface wird durch eine physikalische oder per Software emulierte Netzwerkkarte bereitgestellt
- Endsysteme können mehrere Interfaces haben
- IPv4: 32Bit Adresse, 4 8Bit
- IPv6: 128Bit Adresse, 8 16Bit
Subnets
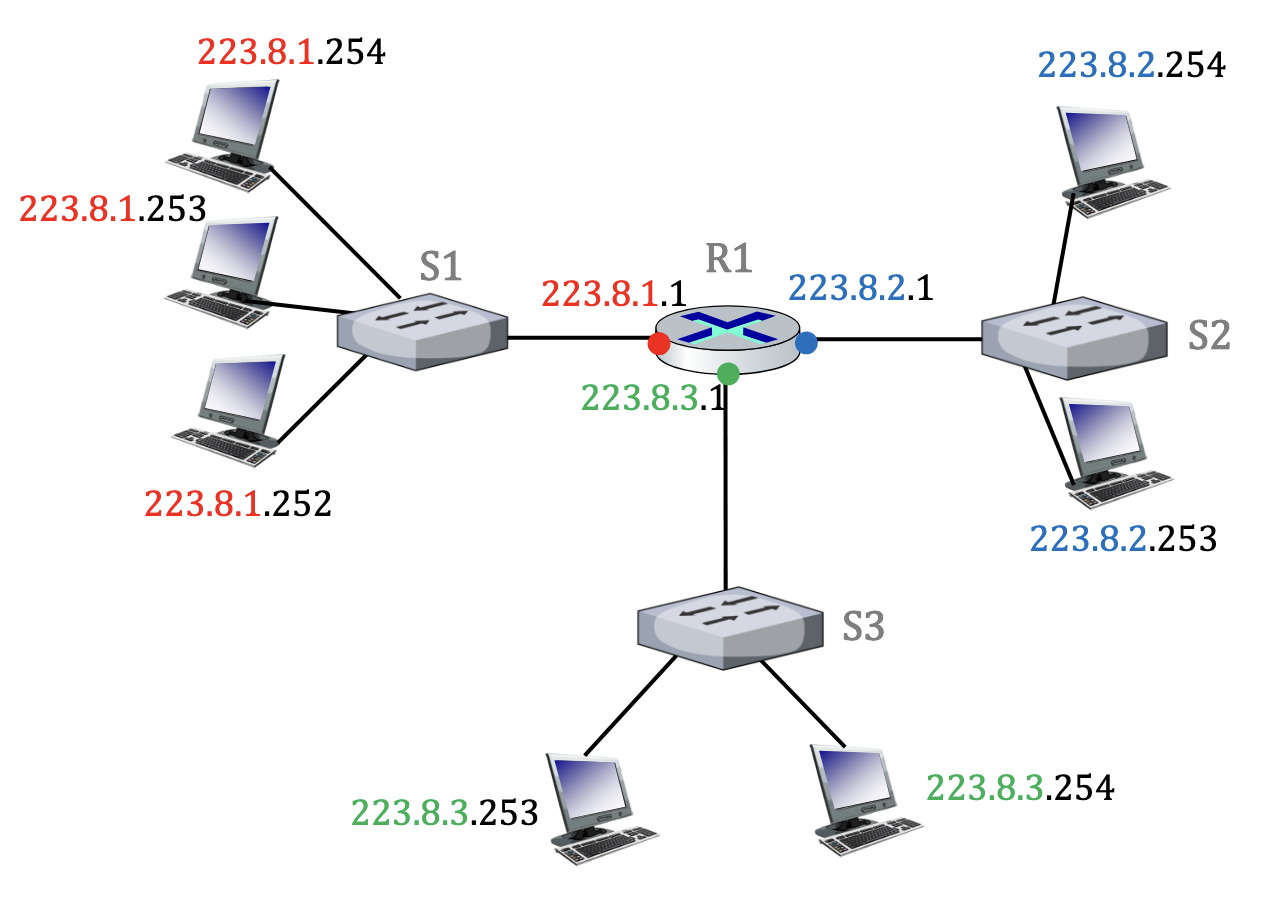
- Eine IP-Adresse hat 2 Bestandteile: Die NetID und die HostID.
- NetID: Ersten bits der Adresse identifizieren ein Netzwerk
- HostID: Identifizieren das Interface eines Gerätes
- Alle Interfaces mit der gleichen NetID formen ein Subnet
- Alle Interfaces eines Subnets können sich direkt erreichen, ohne einen Router zu durchqueren
CIDR CIDR (Classless Inter-Domain Routing) ist ein IP-Adressierungsschema, welches eine granulare Unterteilung der IP-Adressen in Subnets ermöglicht.
- Es werden Suffixe verwendet, die die Anzahl der Bits angeben, die das Netzwerk identifizieren (die NetID)
- Beispiel:
- IPv4-Adresse in CIDR-Notation:
200.100.3.1/16 - ⇒ Die ersten 16 Bits beschreiben das Netzwerk
- 11001000.01100100.00000011.00000001
- IPv4-Adresse in CIDR-Notation:
- Mit CIDR-Notation kann der Adressraum hierarchisch aufgeteilt werden
- Oben: Große Netzblöcke der ISPs
- Unten: Teilnetze von Organisationen
- Ermöglicht Aggregation: Weniger Routen im Internet
- Ermöglicht Segmentierung: Feinere Kontrolle in lokalen Netzen
IPv4 Subnet Masks
- In IPv4 können Subnetzmasken verwendet werden, um den Bereich der NetID und HostID zu kennzeichnen.
- Aufbau der Netzmaske:
- Eine 1 kennzeichnet die Bits in der IP-Adresse für die Addressierung des Subnets
- Eine 0 kennzeichnet die Bits für die Adressierung des Geräteanteils
- Netzmaske:
255.255.255.0
- Durch logisches “AND” der IP-Adresse und der Subnetzmaske erhält man die Netzwerkadresse eines Gerätes.
Netzwerk- und Broadcastadresse
- In einem IPv4-Netzwerk gibt es 2 spezielle, ausgezeichnete Host-Adressen
- Netzwerkadresse: Alle Host Bits auf 0
- Broadcast-Adresse: Alle Host Bits auf 1
- Dazwischen liegen die verfügbaren Adressen für Endgeräte und Netzwerkgeräte
Netzwerke und Host-Adressen
- Durch Verschiebung der Netzwerkmaske um 1 von links nach rechts erhält man Adressbereiche mit einer kleineren Anzahl an Host-Adressen
- /25: 126 Host-Adressen ()
- /26: 62 Host-Adressen ()
- …
- Pro Netzwerkbit verdoppelt sich die Anzahl der Subnets
Konvention für die Vergabe von IP-Adressen
- Default-Gateway erhält die kleinstmögliche IP-Adresse
- Nächstmögliche IPs gehen an zusätzliche Netzwerkgeräte
- Clients erhalten größtmögliche IPs
Broadcast-IP-Adressen Eine Broadcast-IP-Adresse ist eine spezielle IP-Adresse, über die Daten an alle Hosts eines Netzwerks gleichzeitig gesendet werden.
- Alle Geräte im gleichen Subnet empfangen die Nachricht
- Die Adresse ist immer die höchste Adresse eines Subnets
- Ziele der Broadcast-Adresse:
- Auffinden von Netzwerkdiensten
- Gleichzeitige Verteilung von Daten
- Finden von Ethernet-Adressen zu einer IP-Adresse
- Es gibt zwei Arten von Broadcasts:
- Directed Broadcast:
- Broadcast-Adresse eines Netzwerks wird als Zieladresse verwendet
- Alle Hosts im Subnet erhalten die Nachricht
- Router leiten die Nachricht weiter
- Spezialfall Limited Broadcast:
- 255.255.255.255 wird als Broadcast-IP verwendet
- IP Packets werden an alle Hosts des eigenen Subnets weitergeleitet
- Router leiten nicht weiter
- = Ethernet Broadcast
- Directed Broadcast:
IPv4 Multicast-Adressen Eine Multicast-Adresse ist eine Spezielle IPv4-Adresse, die verwendet wird, um Nachrichten an eine ausgewählte Gruppe von Hosts zu senden (nicht an alle Hosts wie bei einem Broadcast)
- IPv4 Multicast-Adressen liegen im Adressbereich von
224.0.0.0bis239.255.255.255, sind von IANA reserviert - Funktionsweise:
- Hosts, die Multicast-Daten empfangen wollen, melden sich beim Router/Switch mittels IGMP (Internet Group Management Protocol) an
- Sender verschickt Packets an Multicast-Adresse
- Router leiten Packets nur an Netzwerksegmente/Ports weiter, in denen Mitglieder dieser Gruppe registriert sind
- Damit Switches die Packets zustellen können wird jeder IPv4 Multicast-Adresse eine Ethernet-Multicast-Adresse zugeordnet
Local Host, Private IPv4-Adressen
- Local Host Adressen: 127.0.0.0/8
- Private IPv4-Adressen:
- 10.0.0.0/8 (10.0.0.0 - 10.255.255.255)
- 172.16.0.0/12 (172.16.0.0 - 172.31.255.255)
- 192.168.0.0/16 (192.168.0.0 - 192.168.255.255)
IPv6 CIDR
- Netzmaske aus IPv4 fällt bei IPv6 weg
- IPv6 verwendet analog zu IPv4 die CIDR-Konvention mit Netzwerk-Präfix (auch routing prefix genannt)
- Typischerweise bekommt ein ISP die ersten 32 Bit einer IPv6 als (Sub-) Netz von einem Regional Internet Registry zugewiesen
- Der ISP vergibt an seine Kunden auf Antrag Company Prefixes
- Beispiel:
- Adresse:
2001:0db8:85a3:0873:1319:8a2e:0370:7347 - Provider Netz-ID:
2001:0db8/32 - Routing Prefix:
2001:0db8:85a3:08/56 - Subnet-ID:
2001:0db8:85a3:0873/64 - Interface-ID:
1319:8a2e:0370:7347
- Adresse:
IPv6-Schreibweise
- Normale IPv6 ist lang, es gibt Vereinfachungen der Schreibweise:
- Zero Compression: Wenn eine Adresse fortlaufende Nullen in mind. 2 aneinanderhängenden 16-Bit-Feldern enthält, werden diese durch
::ersetzt.- Das
::darf in einer Adresse nur 1x vorkommen.
- Das
- Leading Zero Compression: Führende Nullen im 16-Bit-Feld einer IPv6-Adresse können entfernt werden. In jedem Block muss mindestens eine Zahl übrig bleiben → Bei 4 Nullen, die noch nicht gekürzt wurden, muss eine 0 stehen bleiben
- Kleinbuchstaben:
a-fmüssen als Kleinbuchstaben dargestellt werden
- Zero Compression: Wenn eine Adresse fortlaufende Nullen in mind. 2 aneinanderhängenden 16-Bit-Feldern enthält, werden diese durch
IPv6 Unicast
- Unicast-Adressen identifizieren ein einzelnes Interface
- Ein IP Packet, welches an eine Unicast-IP-Adresse adressiert ist, wird auf kürzestem Weg an seine Schnittstelle geleitet
- Local Host:
::1/128 - Link-Local-Unicast: Präfix
fe80::/64- Jedes Interface generiert eine Local-Link-Adresse
- Wird nicht gerouted, dient zur Adressierung eines Subnets
- Unique-Local-Scope (Private)-Adressen: Präfix
fc00::/8&fd00::/8- Dienen zur Adressierung von Hosts innerhalb eines Unternehmensnetzwerkes und werden nur innerhalb eines LAN gerouted.
- Global Scope-Adressen:
2000::/3- Öffentlich routbare IPv6-Adressen, die von der ICANN vergeben werden und im Internet eindeutig sind
- Einer IPv6-Schnittstelle können mehrere IPv6-Unicast-Adressen gleichzeitig zugewiesen werden
Link-Local-Scope-Adressen
- Generiert von Betriebssystem aus MAC-Adresse der Netzwerkkarte:
- 48-Bit MAC-Adresse wird in 2 Hälften aufgeteilt (
00:1a:2b:3c:4d:5e→00:1a:2bund3c:4d:5e) ff:fewird in der Mitte eingefügt, um eine 64-Bit-Adresse zu erhalten:00:1a:2b:ff:fe:3c:4d:5e- Invertieren des 7. Bit von Links:
0000 0000 ...→0000 0010 ...=00:1a:...→02:1a:...(siehe U/L-Bit) - Fertig:
02:1a:2b:ff:fe:3c:4d:5e - Zusammengesetzt mit Link-Local-Prefix:
fe80::02:1a:2b:ff:fe:3c:4d:5e
- 48-Bit MAC-Adresse wird in 2 Hälften aufgeteilt (
U/L-Bit Das 7. Bit einer IPv6-Adresse wird auch “U/L-Bit” genannt, da es anzeigt, ob eine Adresse global oder lokal vergeben wurde.
- 0 → universally administered
- 1 → locally administered
IPv6 Multicast
- Multicast-Adresse: Prefix
ff00::/8- Identifiziert eine Menge von Interfaces, welche typischerweise zu verschiedenen Hosts gehören
- Aufbau:
ff: Multicast Prefix (1111 1111)ffm: Drittes Hex-Zeichen ist Flag- 0 für permanent definierte Adresse
- 1 für temporäre Adresse
ffmn: Viertes Hex-Zeichen für Scope- 1 für Nutzung innerhalb eines Interfaces/Gerätes
- 2: für Nutzung innerhalb eines Subnets ohne Routing
- 8: für Nutzung innerhalb einer Organisation (lokales Routing)
- e: global Scope (weltweites Routing)
- Gruppen-ID (Rest der IPv6-Adresse) ist eine ID für eine Multicast-Gruppe
- 1: Alle IPv6-Geräte im selben LAN
- 2: Alle Router im selben LAN
- …
Duplicate Adress Detection
- Zur Verhinderung von doppelten IPv6-Adressen wird ein Verfahren namens Duplicate Adress Detection (DAD) verwendet
- DAD ist Tiel des ICMPv6 Neighbour Discovery Protocols (NDP) und ermöglicht die Erkennung von Adressen-Konflikten in einem Subnet via sog. Neighbour Solicitation Messages (NS)
- Ablauf:
- Interface generiert Adresse, wird als “vorläufig” markiert
- Gerät sendet ein NS-Packet an die Solicited-Node Multicast Adresse, die aus der generierten Adresse abgeleitet wird
- Wenn niemand Antwortet → Adresse ist frei
- Gerät markiert sie als “preferred” (bevorzugt verwendbar)
Anycast IP
- Eine Anycast-IP-Adresse identifiziert eine ganze Gruppe von Servern, denen eine gemeinsame IP-Adresse (IPv4/IPv6) zugeteilt ist, und die weltweit verteilt stehen.
- Diese eine IP-Adresse wird per Routing-Protokoll (BGP extern, OSPF intern) von den verschiedenen regionalen Standorten über deren Edge-Router publiziert.
- Wenn ein Benutzer eine Anfrage an diese IP-Adresse stellt, wird der nächstgelegene Server basierend auf dem Routing ausgewählt.
- Server wird basierend auf der Forwarding-Tabelle des nächstgelegenen Routers ausgewählt.
DHCP (Dynamic Host Configuration Protocol)
- IPs (v4 und v6) können dynamisch von einem DHCP-Server bezogen werden.
- IPv4-basierende Hosts haben initial keine Adresse.
- IPv6-basierende Hosts generieren selbst eine Local Interface ID & Link Local Adresse (
fe80::/10), verwenden diese initial - DHCP ist ein Protokoll der Anwendungsschicht und verwendet UDP
- Portnummern:
- UDP/67: DHCPv4 Server
- UDP/68: DHCPv4 Client
- UDP/547: DHCPv6 Server
- UDP/546: DHCPv6 Client
- DHCP dient der automatischen Vergabe von IP-Adressen und Parametern.
- IP-Adressen werden auf Zeit gemietet (Lease Time)
- Optimal für mobile Geräte und PCs
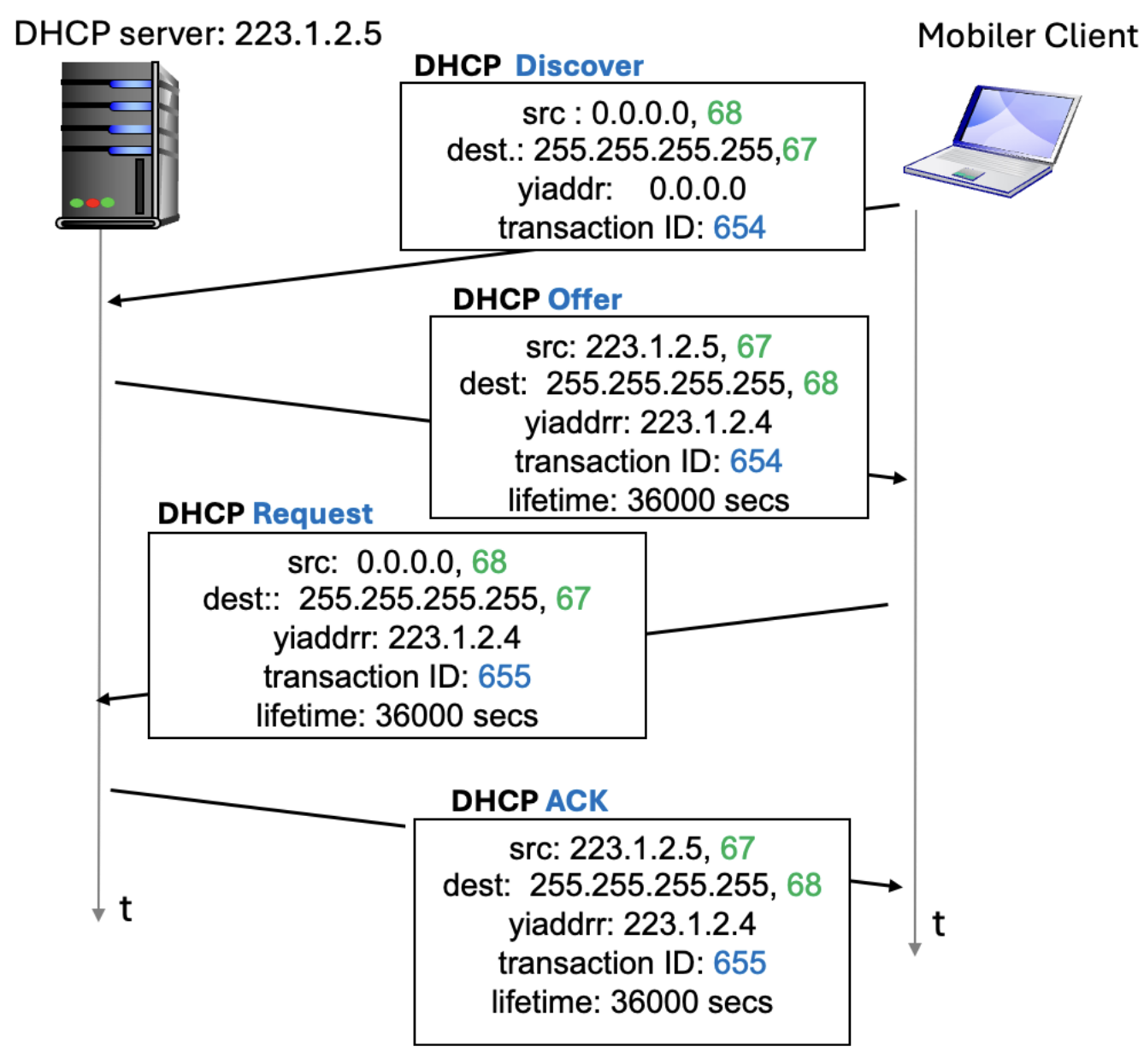
DHCP Nachrichtenaustausch
- DHCP-Client schickt eine DHCP-Discover-Nachricht per IPv4-Source-Adresse (0.0.0.0) an Broadcast-Adresse (255.255.255.255)
- DHCP-Relays (Router) leiten diese Nachrichten an den DHCP-Server weiter
- DHCP-Server antwortet mit einer DHCP-Offer-Nachricht und dem Angebot einer IP-Adresse
- Endsystem beantragt diese IP-Adresse mittels DHCP-Request-Nachricht
- Server vergibt IP-Adresse mittels DHCP-ACK-Nachricht
- Der gesamte Nachrichtenverkehr erfolgt via Broadcasts
DHCPv6
- Nachrichtenversand bei DHCPv6 erfolgt initial per Multicast, dann nur noch per Unicast
- DHCP-Discover per Multicast
- Client verwendet Link Local Adresse und sucht den DHCP-Server per Multicast
- DHCP-Request per Unicast
- Client verwendet Link Local Adresse und kennt aber die IPv6 des DHCP-Servers
- DHCP-Offer und DHCP-ACK per Unicast
- DHCP-Server kennt die Link-Local-Adresse des Clients und verwendet diese
DHCP und IPv4/IPv6
- Die ersten beiden Schritte werden nur initial benötigt, danach merkt der Client sich die IP-Adresse des DHCP-Servers
- Möchte ein Client die IP-Adresse verlängern überspringt er die ersten zwei Schritte und startet sofort mit einer DHCP-Request
- DHCP-Server kann dann mit DHCP-ACK-Nachricht annehmen oder via DHCP-NACK-Nachricht ablehnen, woraufhin der Client eine neue DHCP-Discover-Nachricht senden kann
Network Address Translation (NAT)
- Anzahl der öffentliche IP-Adressen einer Organisation kann begrenzt sein → Zu wenig IP-Adressen für viele Geräte
- Privathaushalte brauchen nur eine IPv4-Adresse, die vom Provider temporär zugewiesen wird, aber alle Geräte sollten Internetfähig sein
- Idee: Vergebe private (weltweit nicht eindeutige) IP-Adressen an Systeme im Privaten Netzwerk
- Router/Firewall zur Anbindung ans Internet übersetzt die lokalen IPs in eine weltweit eindeutige IP-Adresse
- Portnummern werden genutzt, um verschiedene Geräte voneinander zu unterscheiden
NAT Overloading
- Nicht öffentliche IP-Adressen der Geräte werden auf eine öffentliche Adresse gemapped
- Alle Packets, die das lokale Netzwerk verlassen, haben die gleiche öffentliche Outside-NAT-IP-Adresse, aber unterschiedliche Outside-TCP-Portnummern.
- Funktionsweise:
- Bei ausgehenden Packets ersetzt der Router die Sender-IP und den TCP-Port durch die Router-IP und einen Port im Router
- Empfänger schickt Antworten an Router
- In einer NAT-Table speichert der Router die Beziehnung zwischen der IP-Adresse und dem Port des Clients mit der eigenen IP-Adresse und dem genutzten Port für 24h
- Bei eingehenden Packets ersetzt der Router die IP-Adresse und den Port erneut und gibt das Packet weiter an das lokale Gerät
NAT Traversal mit Port Forwarding
- Selbe Idee wie bei NAT, allerdings bekommt ein Server einen festen Port, an den alle öffentlichen Anfragen weitergeleitet werden
ARP-Request und ARP-Response Messages
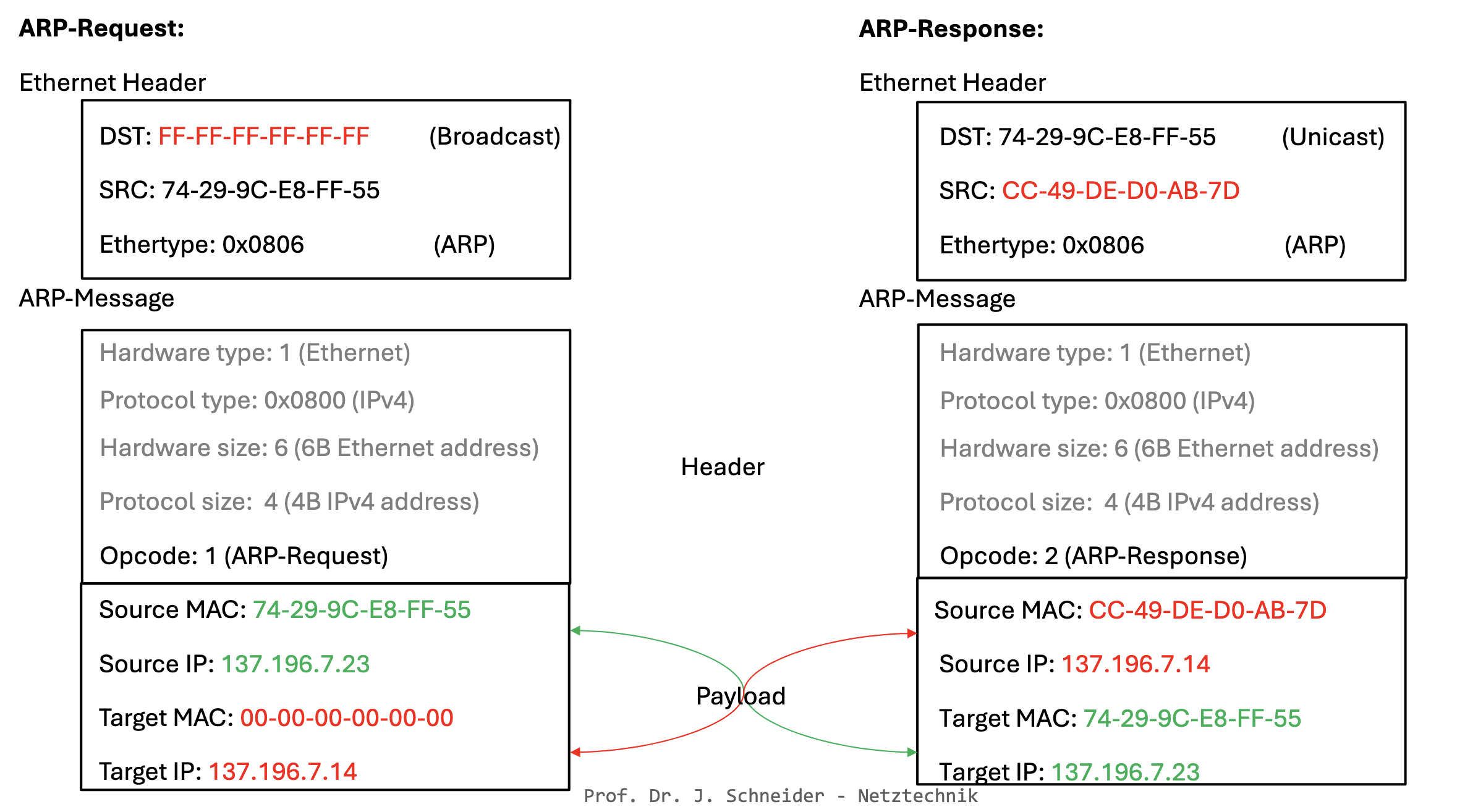
ARP: Address Resolution Protocol
- Um IPv4-Adressen einer MAC-Adresse zuzuordnen wird das Address Resolution Protocol verwendet
- ARP ist ein Layer-2-Protokoll
- Jedes System in einem LAN hat einen ARP-Cache, in dem Zuordnungen von IP- zu MAC-Adresse gespeichert werden
- ARP verwendet Ethernet
- Szenario:
- C möchte eine Nachricht an B schicken, MAC-Adresse von B ist nicht im Cache von C
- C schickt ARP-Query als Ethernet Broadcast Frame
- Destination-MAC: FF-FF-FF-FF-FF-FF
- Alle Systeme erhalten die Anfrage
- ARP-Request enthält IP-Adresse von B und MAC- und IP-Adresse von C als ARP-Payload
- B empfängt ARP-Request, erkennt eigene IP und antwortet C (Unicast) mit eigener MAC-Adresse in Form einer ARP-Response
- C trägt die MAC-Adresse und IP-Adresse von B in ARP-Cache ein (mit TTL-Wert)
- C verschickt eigentliche Nachricht
Routing zwischen zwei Subnets
- ARP funktioniert via Router auch über Subnet-Grenzen hinweg
- Router besitzt pro Interface eine eigene ARP-Table
- Im diesem Fall wird ein Zwischenschritt über den Router gemacht, der dann erneut ARP verwendet, um den Host im anderen Subnet zu finden
- Ablauf:
- Schritt 1: Host A → Router
- Schritt 2: Router → Host B
ICMP: Internet Control Message Protocol
- Kontroll- und Diagnose-Protokoll
- ICMP ist ein Layer-3-Protokoll und verwendet IP, um Nachrichten zu transportieren
- Kann zur Überprüfung der Verbindung zwischen zwei Hosts eingesetzt werden
- Aufbau:
- Type (1 Byte): Art der Nachricht
- Code (1 Byte): Verfeinerung für Art
- Checksum (2 Byte): Internet Checksum für die Nachricht
- Content
IMCP-Types & -Codes
- Eine ICMP-Message wird über Type und Code beschrieben
- Type stellt allgemeine Art der Nachricht dar, z.B.:
- Fehler
- Request
- Reply
- Code steht für konkrete Bedeutung der Nachricht, z.B.:
- Konkreter Fehler
- Request für was
- Reply zu was
Traceroute
- Schickt ICMPv4-Type-8-Code-0-Echo-Request mit TTL = 1 ab
- Router 1 blockiert Packet, gibt Nachricht zurück
- TTL wird auf 2 gesetzt
- Router 2 blockiert Packet, gibt Nachricht zurück
- Prozess wird so lange wiederholt, bis Ziel erreicht ist
ICMPv6: Neighbour Discovery
- Ersatz für ARP in IPv6
- Verwendet ICMPv6-Nachrichten
- Ergebnisse der Anfragen werden im sog. Neighbour Discovery Cache gespeichert
- ICMPv6-Nachrichten werden als Multicast-Packets im Subnetz verteilt
- Besteht aus Solicitation und Advertisment
- Solicitation ist Multicast-Nachricht, die an Netzwerk gesendet wird, wenn nach MAC-Adresse gesucht wird
- Advertisment ist Antwort auf Solicitation, enthält selbe Target-Adresse
MTU Path Recovery mit ICMPv6
- Bei IPv6 werden Packets vom Sender fragmentiert, nicht vom Router
- Stellt ein Router auf dem Weg eines Packets zum Ziel fest, dass die Nachfolgende Schnittstelle eine zu kleine MTU-Größe unterstützt, sendet der Router eine ICMPv6-Type-2, Code-0 Nachricht an den Sender und informiert ihn im Payload über die maximal mögliche MTU
- Der Sender fragmentiert die Packets daraufhin mit der neuen MTU und verschickt die Frames erneut