Chomsky-Hierarchien
| Typ der Sprache | Sprache / Grammatik | Akzeptiert von |
|---|---|---|
| Typ-0 | Rekursiv aufzählbare | Turing-Maschine (TMs) |
| Typ-1 | Kontextsensitive | Linear Bandbeschränkte Automaten (LBAs) |
| Typ-2 | Kontextfreie | Kellerautomaten (KA) / Push-Down Automaton (PDA) |
| Typ-3 | Reguläre | Endlichen Automaten |
Umwandlung NEA in DEA (Potenzmengenkonstruktion)
Umwandlung kann mit tabellarischer Darstellung gemacht werden:
| Von ( = / ) | NEA | DEA |
|---|---|---|
| Start | (Startzustand) | (Startzustand) |
| … | … | … |
“Quantenzustände”, also Übergange in einem DEA bei denen ein NEA sich in zwei verschiedenen Zuständen befinden könnte, werden durch das Zusammenfassen der beiden Zustände in einem weiteren Zustand des DEA abgebildet ()
Die Tabelle wird gelesen als: “Ich befinde mich in Zustand , welcher equivalent zu ist und mache eine . Dadurch lande ich beim NEA in … und beim DEA in …”
Regulärer Ausdruck aus NEA (Zustandselimination)
Mit der Zustandselimination kann aus einem NEA ein regulärer Ausdruck erzeugt werden. Die Zustandselimination verwendet sog. verallgemeinerte NEAs (VNEAs), um den regulären Ausdrück möglichst einfach zu erreichen (links ist ein NEA, rechts ein VNEA):
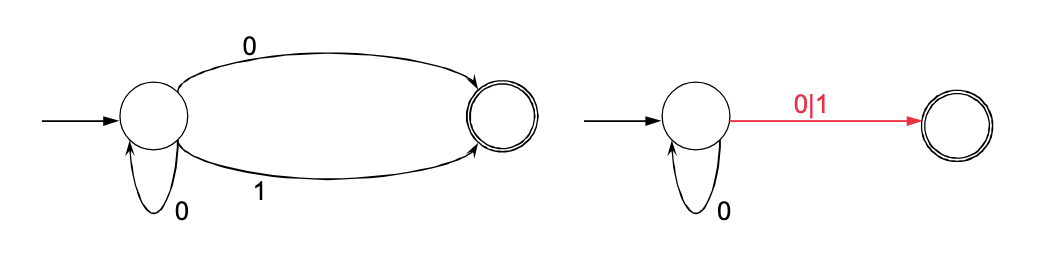
Bei der Zustandselimination wird folgendes gemacht:
- Wandle den NEA in einen VNEA um
- Wiederhole für alle Endzustände :
- Eliminiere (iterativ, also nacheinander, nicht gleichzeitig!) alle Zustände außer dem Startzustand und .
- Bilde einen regulären Ausdruck aus dem finalen Automaten
- Vereinige die Ausdrücke für alle Endzustände q mit einem logischen Oder (
|)- Bilde die Summe aller entstandenen regulären Ausdrücke
Reguläre Ausdrücke, EAs und Syntaxdiagramme
Zu jedem regulären Ausdruck gibt es einen endlichen Automaten, den man aus dem regulären Ausdruck hinaus erschließen kann.
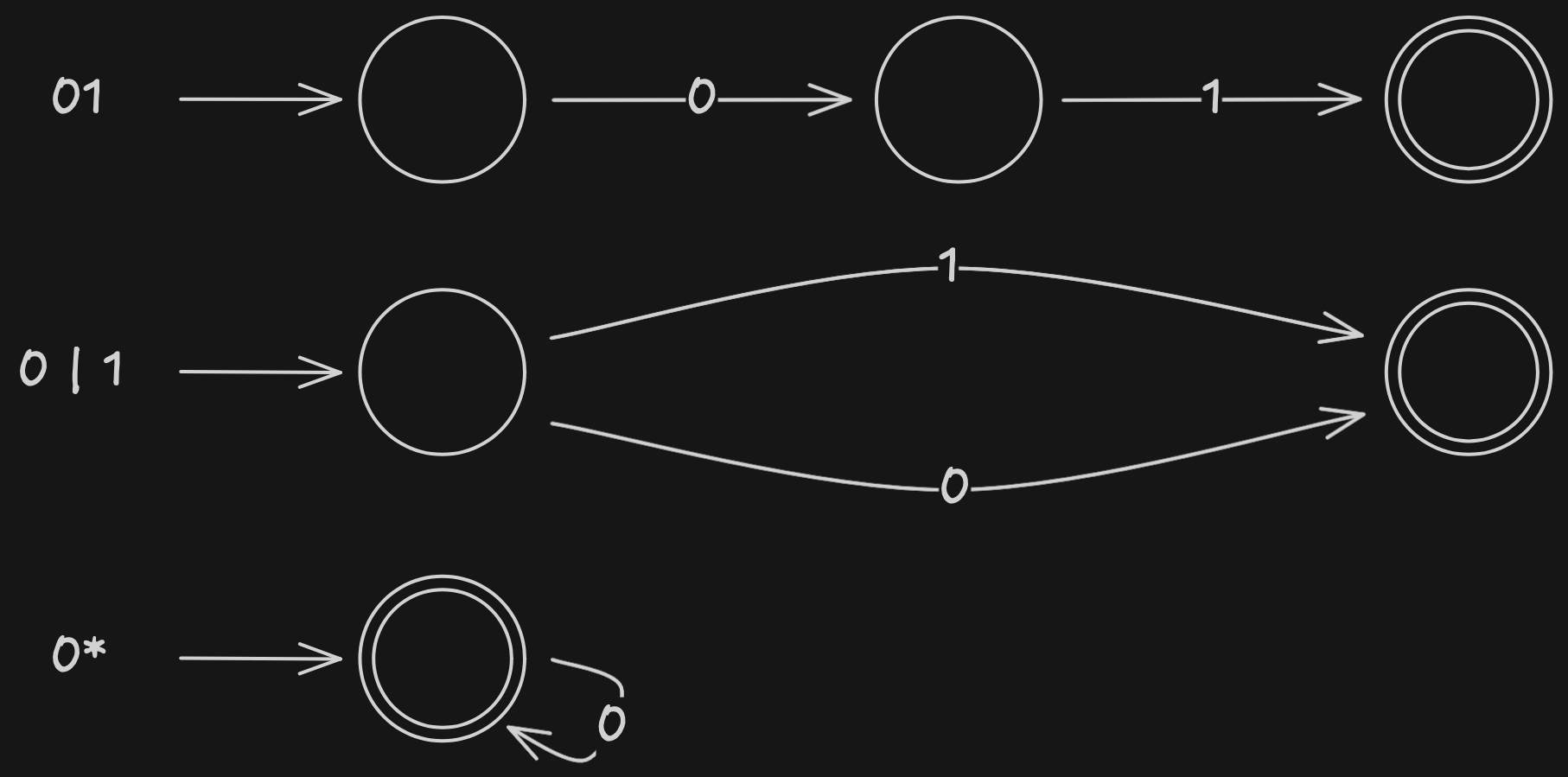
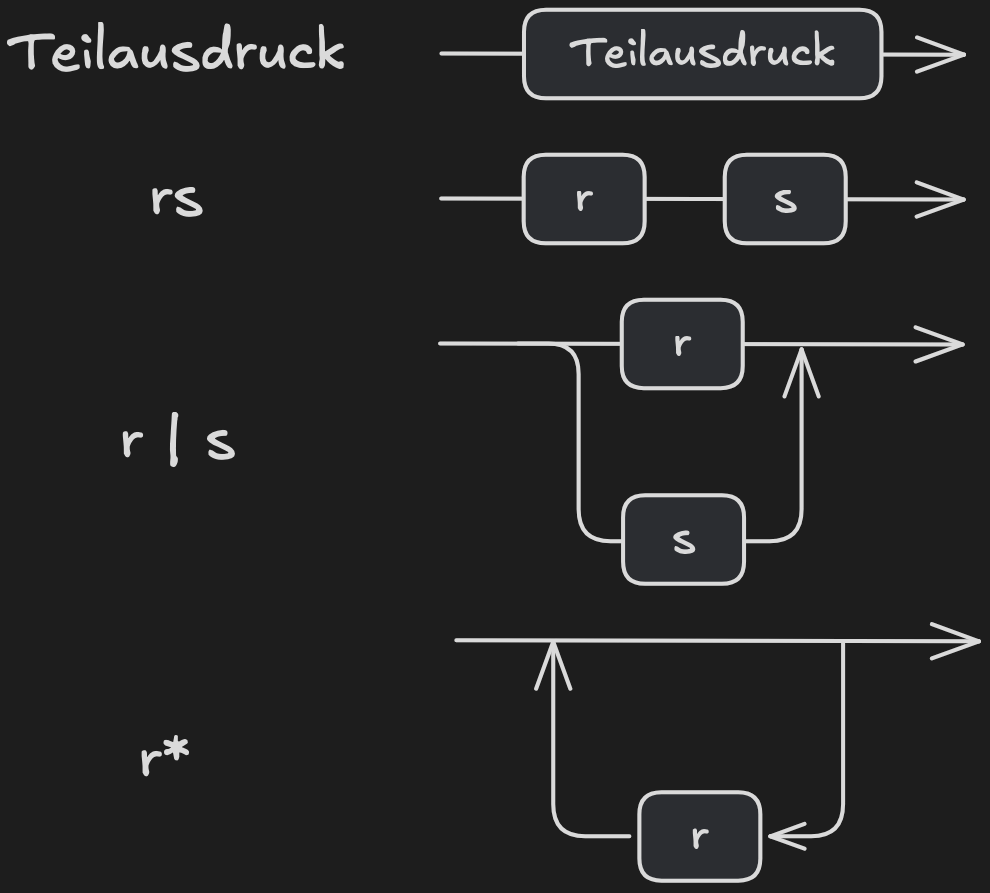
Ein regulärer Ausdruck lässt sich mit einem Syntaxdiagramm graphisch darstellen:
Lexikographische Ordnung
Beim Sortieren von Wörtern wird folgende Ordnung verwendet (angenommen, es gibt zwei Wörter und ):
- falls
- Falls : Nach Buchstaben innerhalb des Wortes ()
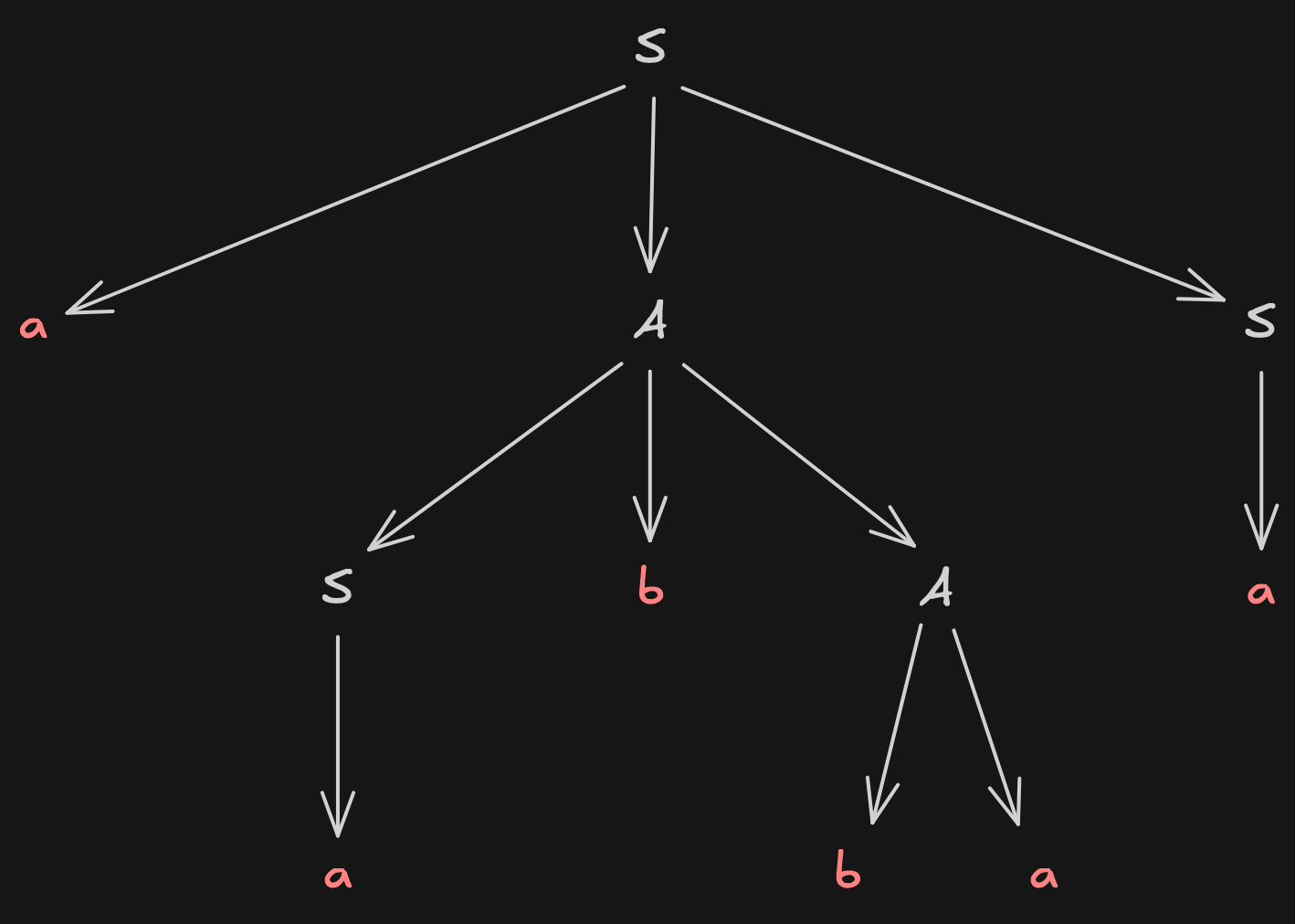
Ableitungsbäume
Zu einer kontextfreien Grammatik kann ein Baum erstellt werden, der die Ableitung symbolisiert. Damit ein Baum als Ableitungsbaum bezeichnet werden darf, müssen folgende Bedingungen erfüllt sein:
- Die Wurzel muss mit markiert sein
- Jeder Knoten ist mit (einem (Nicht-) Terminal) markiert
- Jeder innere Knoten ist mit einem (einem Nichtterminal) markiert
- Wenn ein innerer Knoten mit (einem Nichtterminal) markiert ist und seine Nachfolger von links nach rechts mit (einem Terminal), dann muss sein.
- Wenn ein Knoten mit markiert ist, ist ein Blatt und der einzige Sohn seines Vaters
Ein Ableitungsbaum ist eine natürliche Beschreibung für die Ableitung einer bestimmten Satzform der Grammatik G, die man erhält, wenn man die Markierungen aller Blätter von links nach rechts liest. Diese Zeichenkette wird auch Front des Ableitungsbaumes genannt.
Ableitungsbaum für die Linksableitung
Pumping Lemma
Das Lemma dient als Negativ-Test, um per Widerspruch zu beweisen, dass eine Sprache nicht regulär ist. Es besagt: Jedes ausreichend lange Wort einer regulären Sprache enthält einen Teilbereich (eine nicht-leere Schleife), den man beliebig oft wiederholen („aufpumpen“) kann, ohne die Sprache zu verlassen: Scheitert dies an einem Beispielwort, ist die Sprache nicht regulär.
Halteproblem der TM
Das Halteproblem ist unentscheidbar: Es existiert bewiesenermaßen (durch Diagonalisierung) kein Algorithmus, der für jede Turing-Maschine und Eingabe vorhersagen kann, ob sie stoppt oder endlos läuft. Es ist lediglich semi-entscheidbar, da man ein Anhalten zwar erkennen kann, eine Endlosschleife durch bloßes Simulieren jedoch nie sicher identifiziert wird.
LL(1)-Grammatiken, FIRST & FOLLOW
LL(1) steht für Lesen von links, Linksableitung und 1 Zeichen Vorschau (Lookahead). Damit eine Grammatik LL(1) ist, muss der Parser stets eindeutig ohne Raten entscheiden können, welche Regel gilt.
K.O.-Kriterien:
- Linksrekursion
- Gemeinsame Präfixe: Diese verletzen die Eigenschaft sofort, da sie die Eindeutigkeit zerstören.
FIRST- und FOLLOW-Mengen
Sie dienen der Konstruktion der Parsing-Tabelle.
- FIRST: Enthält alle möglichen Startzeichen einer Variablen (inklusive ).
- FOLLOW: Enthält alle Zeichen, die im Wort direkt hinter der Variablen folgen können (niemals , oft das Endsymbol $$$).
Bedingung: Für LL(1) müssen die FIRST-Mengen alternativer Regeln disjunkt (überschneidungsfrei) sein.
Minimierung endlicher Automaten
Zum Minimieren von EAs kann folgender Algorithmus verwendet werden:
- Stelle eine Tabelle aller Zustandspaare von auf, mit ungleich
- Markiere alle Paare mit genau einem Endzustand
- Für jedes unmarkierte Paar , teste für jedes Symbol ob markiert
- Falls ja, markiere auch
- Wiederhole 3. bis sich keine Änderung mehr ergibt
- Verschmelze alle unmarkierten Zustandspaare zu einem neuen Zustand
Zuerst stellt man eine Tabelle auf, in der Angekreuzt wird, von welchem Zustand man welchen anderen Zustand erreichen kann. In den Zeilen wird der Startzustand weggelassen, in den Spalten der Endzustand:
| Z0 | Z1 | Z2 | Z3 | Z4 | |
|---|---|---|---|---|---|
| Z0 | ------ | ------ | ------ | ------ | ------ |
| Z1 | ------ | ------ | ------ | ------ | |
| Z2 | ------ | ------ | ------ | ||
| Z3 | ------ | ------ | |||
| Z4 | ------ |
Dann werden alle Paare, bei denen genau einer der beiden ein akzeptierender Endzustand ist, markiert.
Als nächstes wird überprüft, was passiert, wenn bei jedem Zustand eines unmarkierten Zustandspaares die selbe Eingabe gemacht wird. Man erhält ein neues Paar . Wenn das neue Paar bereits markiert ist, bedeutet das, dass nach Lesen des Symbols die Zustände in einen bereits bekannt unterschiedlichen Zustand übergehen. Man markiert .
Nachdem dies für den Rest der Tabelle wiederholt wurde, sind alle markierten Paare sicher verschieden. Alle unmarkierten Paare sind äquivalent und können kombiniert werden. Visuell kann man sich Vorstellen, dass die Kreise “übereinander geschoben werden”, da die Pfeile zu den jeweiligen Kreisen des Automaten für den neuen Kreis einfach kombiniert werden.
Vereinfachungen
Ziel bei der Vereinfachung ist, das Format der Produktionen einzuschränken, ohne deren Fähigkeit zur Erzeugung von Sprachen zu beschneiden. Eine kontextfreie Grammatik lässt sich durch folgende Maßnahmen vereinfachen:
- Eliminierung von ε-Regeln: Es gibt keine Produktionen der Form wenn
- Eliminieren nutzloser Symbole: Jede Variable und jedes Terminal von erscheint in der Ableitung mindestens eines Wortes aus
- Eliminieren von Kettenregeln: Es gibt keine Produktionen der Form , wenn und Variablen sind
Eliminieren von ε-Regeln
- Bestimme alle Nichtterminale, die in ein ε umgewandelt werden können:
- Bestimme alle Nichtterminale, aus denen das leere Wort ableitbar ist:
- Für jede Regel, deren Rechte Seite ein Nichtterminal aus enthält, fügen wir eine Regel ohne dieses Nichtterminal hinzu.
- Eliminiere alle ε-Regeln (entferne das ε aus allen Umformungen und entferne die Umformung selbst, falls das ε nicht verodert ist)
Beispiel:
, ,
Hier führt zu einem leeren Wort, also “markieren” wir es im 1. Schritt. Da sich aus ableiten lässt, markieren wir auch dies. In Schritt 3 wird umgeformt, da wir das in der Ableitung dort markiert haben:
, ,
Im letzten Schritt entfernen wir das ε aus der Ableitung von :
, ,
Eliminieren nutzloser Symbole
Beim Eliminieren von nutzlosen Symbolen wird darauf geachtet, welche Symbole nützlich für die Grammatik sind. Ein Symbol heißt nützlich, wenn mit seiner Hilfe mindestens ein Terminalwort erzeugt werden kann, also wenn gilt:
mit und .
Beim Eliminieren von nützlichen Symbolen wird also darauf geachtet, dass zwei Aspekte der Nützlichkeit für jedes Symbol gegeben sind:
- Aus muss eine Terminalzeichenkette ableitbar sein (Lemma 1)
- muss Teil einer Zeichenkette sein, die aus ableitbar ist (Lemma 2)
Lemma 1 beschäftigt sich mit der Erreichbarkeit von Symbolen. Ein Symbol muss erreichbar sein, also vom Startsymbol aus in einer Folge von Produktionen irgendwann erzeugt werden. Bei Lemma 1 werden alle Symbole, die niemals vom Startsymbol aus erreicht werden können, eliminiert. Der Algorithmus hierzu sieht so aus:
- Merke dir alle Nichtterminale, die per Ableitung in ein Terminal verwandelt werden können ( ⇒ A muss ein Nichtterminal produzieren, was in der Menge aller Wörter steht)
- Prüfe, welche Ableitungen zu den gemerkten Nichtterminalen führen, und markiere diese, bis alle Ableitungen durchlaufen sind. Sobald alle anderen Ableitungen angeschaut und markiert sind, entferne alle nicht markierten Ableitungen.
Lemma 2 hingegen eliminiert nicht erzeugende Symbole. Ein Symbol ist erzeugend, wenn es ein Wort bestehend aus nur Terminalsymbolen ableiten kann. Alle Symbole, die kein terminales Wort erzeugen können, sind ebenfalls nutzlos.
- Starte bei und durchlaufe alle möglichen Ableitungen, um zu sehen, welche Nichtterminale erreicht werden können. Entferne alle Ableitungen, die nicht erreicht werden können.
Eliminieren von Kettenregeln
Kettenregeln tragen zur Erzeugung eines Wortes nichts bei. Sie haben folgende Form und können durch drei Schritte eliminiert werden:
- Entfernen von Zyklen: Gibt es Nichtterminale, die einen Zyklus erzeugen (z.B. ), fügen wir ein neues Nichtterminal hinzu und ersetzen alle durch .
- Umnummerierung: hat nun Elemente. Wir bezeichen diese mit , so dass gilt: Wenn , dann ist
- Ersetzen von Kettenregeln: Wenn noch Regeln wie dann kann jede Regel ersetzt werden durch
Chomsky-Normalform (CNF)
Eine kontextfreie Grammatik ist in CNF, wenn alle ihre Produktionen eine der folgenden Formen haben:
- (nur vorhanden, wenn das leere Wort erzeugt)
(mit und )
⇒ Zu jeder kontextfreien Sprache lässt sich eine Grammatik in CNF angeben, so dass ist.
Zum Erzeugen der CNF einer Grammatik muss die Grammatik maximal vereinfacht vorliegen. Man beachte die Produktionen :
- Wenn vorhanden ist: Ersetze durch , füge neue Produktion hinzu, ersetze alle anderen durch .
- Wenn kein vorhanden ist: Betrachte die Produktion und ersetze dies durch die Produktionen .
Wortproblem & CYK-Algorithmus
Wenn eine kontextfreie Grammatik in der CNF sowie ein Wort gegeben sind, stellt sich die Frage, ob das Wort Teil der Sprache ist (). Dies kann mit dem Cocke-Younger-Kasami-Algorithmus (CYK) beantwortet werden.
Die Idee lautet wiefolgt: Für jedes Teilwort der Sprache wird die Menge der Nichtterminale berechnet, die benötigt werden, um das Wort zu erzeugen. Man dringt hierbei von kleineren zu immer größeren Teilwörtern vor. Am Einfachsten ist dies Tabellarisch zu erreichen.
Beispiel
- Gesuchtes Wort
- Produktionen: , , ,
Es wird eine Tabelle mit Zeilen und Spalten aufgestellt, wobei :
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | ------ | |||||
| 3 | ------ | ------ | ||||
| 4 | ------ | ------ | ------ | |||
| 5 | ------ | ------ | ------ | ------ | ||
| 6 | ------ | ------ | ------ | ------ | ------ |
Entlang der Hauptdiagonalen werden dann die Terminale von eingetragen. Dann werden die Terminale durch die möglichen Nichtterminale, durch die sie direkt erzeugt werden können ersetzt:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | B | |||||
| 2 | ------ | B | ||||
| 3 | ------ | ------ | A, C | |||
| 4 | ------ | ------ | ------ | B | ||
| 5 | ------ | ------ | ------ | ------ | A, C | |
| 6 | ------ | ------ | ------ | ------ | ------ | A, C |
Hier beginnt der Algorithmus. Zuerst schauen wir uns an. Da es keine Produktion gibt, die erzeugt, tragen wir ”{}” ein:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | B | {} | ||||
| 2 | ------ | B | ||||
| 3 | ------ | ------ | A, C | |||
| 4 | ------ | ------ | ------ | B | ||
| 5 | ------ | ------ | ------ | ------ | A, C | |
| 6 | ------ | ------ | ------ | ------ | ------ | A, C |
Bei hingegen gibt es Produktionen, die entweder oder erzeugen, weshalb wir die Terminale für die Produktionen () dort eintragen. Weiter geht es danach mit , , , , , usw.
Nachdem die Tabelle gefüllt ist, muss in der oberen rechten Ecke das Startsymbol zu finden sein. Falls es vorhanden ist, ist das Wort in der Sprache enthalten.