Formale Systeme
Post’sche Produktionssysteme
Ein Post’sches Produktionssystem ist eine spezielle Art von formalem System. Sie bestehen aus einem Axiom, d.h. einer bestimmten Kombination von Zeichen, die als gegeben angenommen werden und einer Menge von Regeln, die bestimmt, in welche Zeichenfolge eine gegebene Zeichenfolge umgewandelt werden kann. Die durch die Regeln aus dem Axiom erzeugbaren Zeichenketten nennt man Sätze des Produktionssystems.
Beispiel:
Axiom: Regeln:
Im genannten Beispiel stehen , und für Symbole aus dem System, während die Zeichen und für Variablen stehen, die durch beliebige Zeichenketten aus dem System ausgetauscht werden können. , und werden hierbei Terminale, und Nichtterminale genannt (“Terminal” → , und können nicht mehr ersetzt werden).
Endliche Automaten
Endliche Automaten können als “Black Box” betrachtet werden, die sich aufgrund einer Folge von Eingaben in einem bestimmten Zustand befindet. Je nach aktuellem Zustand und Eingabe geht der endliche Automat (EA) in einen weiteren Folgezustand über. Der EA besitzt zudem einen oder mehrere ausgezeichnete Zustände (Endzustände). Wenn der endliche Automat nach einer Folge von Eingaben einen Endzustand erreicht, wird diese Eingabe vom Automaten akzeptiert.
Zustandsdiagramm
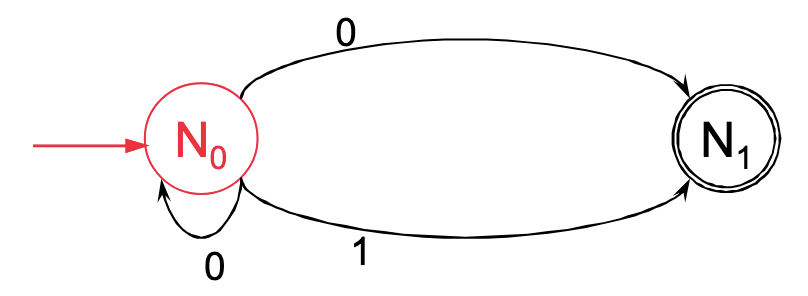
Einen EA kann auch visuell dargestellt werden. Ein Zustandsdiagramm für einen Automaten, der den Eintritt in einem Schwimmbad kontrolliert, sieht so aus:
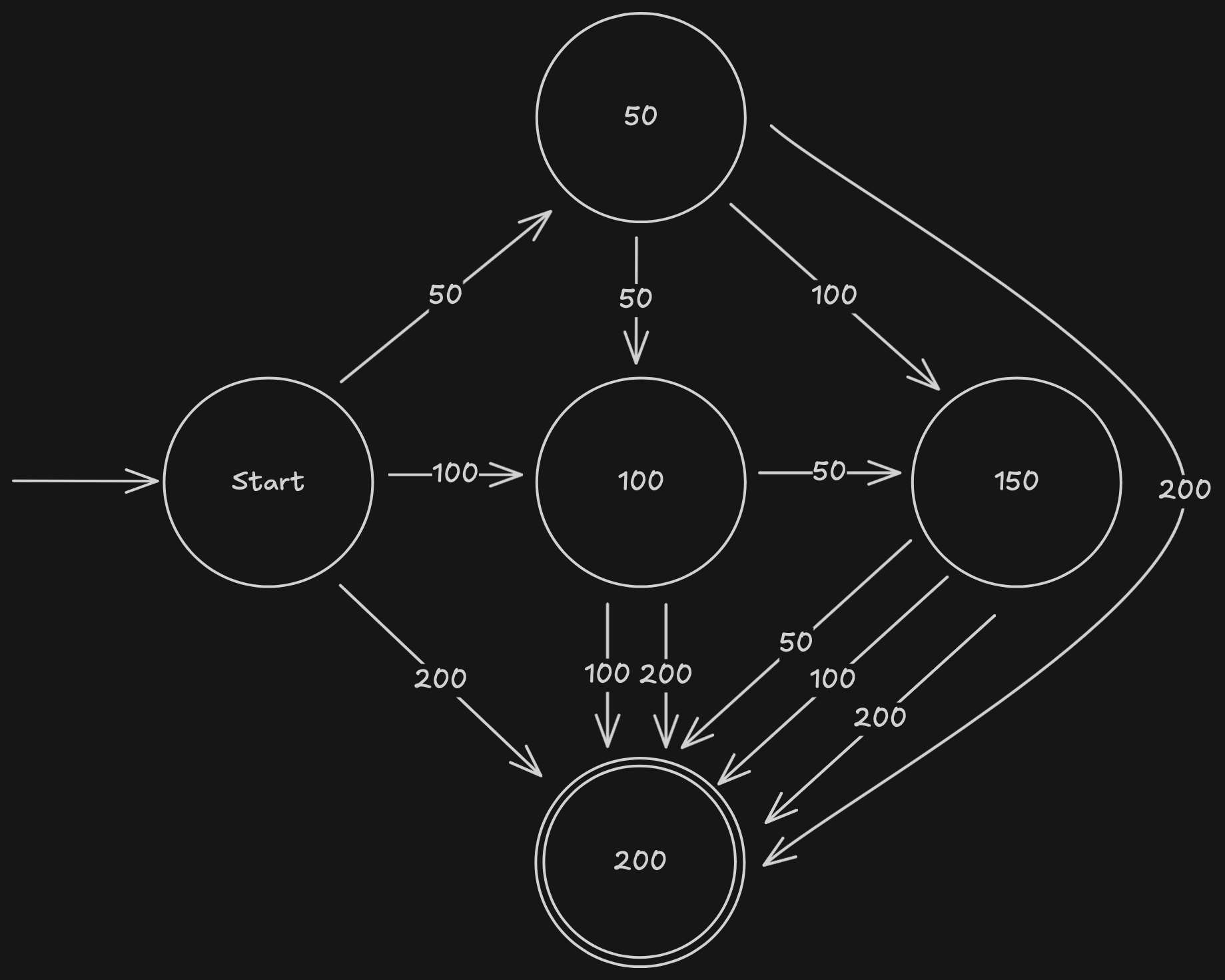
Hierbei kostet der Eintritt 2€. Der Automat akzeptiert 50 Cent sowie 1€- und 2€-Münzen. Sobald mindestens 2€ eingeworfen sind, öffnet der Automat das Drehkreuz (befindet sich in einem akzeptierenden Endzustand).
Die Zustände des Automaten sind als Kreise dargestellt. Die Übergänge zwischen den Kreisen sind die Pfeile, die Eingaben, die zum Übergang führen, sind die Symbole an den Pfeilen. Der Startzustand ist der Kreis mit dem Eingangspfeil, der Endzustand der Doppelkreis.
Formale Definition
Ein EA kann definiert werden durch:
Die Symbole stehen für:
- : Endliche Menge von Zuständen
- : Endliches Eingabealphabet
- : Die Übergangsfunktion
- : Der Anfangszustand
- : Die Menge der akzeptierenden Endzustände
Die Eingabe der Übergangsfunktion ist ein Paar bestehend aus dem aktuellen Zustand und dem gelesenen Symbol . Die Ausgabe ist genau ein Folgezustand .
EAs mit Ausgabe
Bei endlichen Automaten mit Ausgabe gibt es zwei Möglichkeiten, diesen Auszugeben: Mit dem erreichten Zustand und mit dem durchgeführten Übergang.
Moore-Automat
Bei einem Moore-Automat wird beim Erreichen eines Zustands eine Ausgabe gemacht. Er kann definiert werden als:
Wobei:
- : Endliche Menge von Zuständen
- : Endliches Eingabealphabet
- : Endliches Ausgabealphabet
- : Die Übergangsfunktion
- : Die Ausgabefunktion
- : Der Anfangszustand
Mealy-Automat
Der Mealy-Automat hingegen macht eine Ausgabe, wenn ein Übergang durchlaufen wird. Er kann definiert werden als:
Wobei:
- : Endliche Menge von Zuständen
- : Endliches Eingabealphabet
- : Endliches Ausgabealphabet
- : Die Übergangsfunktion
- : Die Ausgabefunktion
- : Der Anfangszustand
Die Mealy- und Moore-Automaten unterscheiden sich ausschließlich darin, dass der Moore-Automat technisch gesehen bereits im Startzustand eine Ausgabe macht. Anderweitig sind sie equivalent. Zu jedem Moore-/Mealy-EA findet man einen Mealy-/Moore-EA, der für alle Eingabeketten dieselbe Ausgabe liefert (insofern die Ausgabe des Startzustandes vernachlässigt wird).
(Fehlend hier: Zeichnungen)
Beispiel zu einem Mealy-Automat zur Berechnung des Modulo 3:
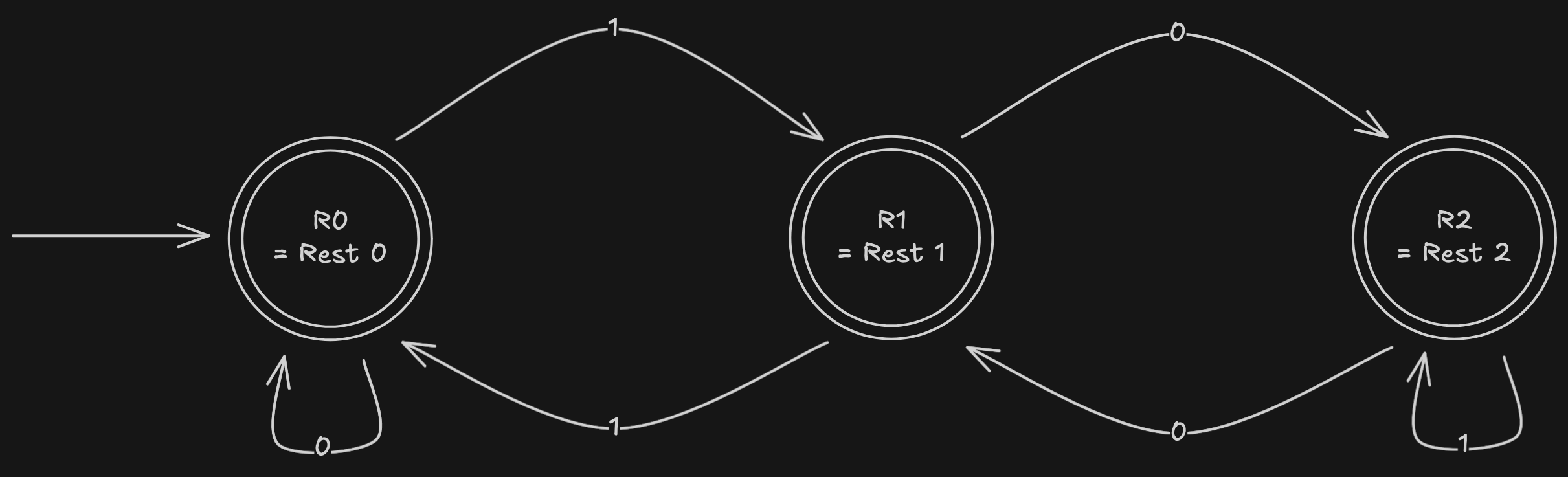
Akzeptierte Folgen
Wenn eine Eingabe komplett gelesen ist und der Zustandsspeicher einen Endzustand enthält ist die Zeichenfolge akzeptiert.
Alphabete, Wörter und Sprachen
Symbole
Die bisherigen Eingaben für z.B. den Eintrittsautomaten (50, 100, 200) waren atomare Symbole für Geldstücke. Der Lesekopf liest das Eingabeband symbolweise. Die Eingabesymbole zusammen ergeben ein Eingabewort. Man kann Symbole auch Buchstaben nennen.
Alphabete
Die Menge der möglichen Eingabesymbole bildet das Eingabealphabet. Formal wird meist verwendet, also:
Allgemein können die Symbole bis verwendet werden:
Wörter
Die endlich langen Zeichenfolgen, die über einem Alphabet gebildet werden können, heißen Wörter über . Sie werden durch die Aneinanderreihung von Symbolen oder bereits existierenden Wörtern erzeugt.
Wörter können:
- Konkateniert werden (aneinandergereiht werden)
- Potenziert werden (, )
- Umgekehrt werden ( (Wort wird rückwärts gelesen))
Die Menge aller Wörter über wird geschrieben:
- Jeder Buchstabe ist auch ein Wort über , also
- Sind , so ist auch
- ist das leere Wort über jedem Alphabet . Es gilt
Beispiel:
Außerdem kann die Länge eines Wortes mit bezeichnet werden:
Aber Obacht! Es geht immer um die Länge der Symbole, nicht der Zeichen/Ziffern. Beim Eintrittsautomaten beispielsweise gilt:
Lexikographische Ordnung
Beim Sortieren von Wörtern wird folgende Ordnung verwendet (angenommen, es gibt zwei Wörter und ):
- falls
- Falls : Nach Buchstaben innerhalb des Wortes ()
Sprachen
Eine Sprache über einem Alphabet ist eine Menge von Wörtern über . L ist also eine Teilmenge von ().
Folgende Operationen können auf Sprachen ausgeführt werden:
- Konkatenation:
- Potenz: ,
- Reverse:
Kleensche & positive Hülle
Die Kleensche Hülle eines Alphabets oder einer formalen Sprache ist die Menge aller Wörter, die durch beliebige Konkatenation von Symbolen des Alphabets bzw. von Wörtern der Sprache gebildet werden können, wobei das leere Wort inbegriffen ist. Die positive Hülle hingegen enthält das leere Wort nur dann, wenn die Sprache selbst das leere Wort beinhaltet. Wenn also , ist auch
Reguläre Ausdrücke & Grammatiken
Die von endlichen Automaten akzeptierten Sprachen lassen sich durch einfache Ausdrücke beschreiben, die man als regulären Ausdrücke bezeichnet.
Die Menge der regulären Ausdrücke (über dem Alphabet ) ist definiert durch:
- ist ein regulärer Ausdruck
- ist ein regulärer Ausdruck
- Für jedes ist ein regulärer Ausdruck
- Sind und reguläre Ausdrücke, so auch
- → Vereinigung
- → Konkatenation
- → Kleene Stern
Falls nicht geklammert ist gilt vor und vor |.
Semantik regulärer Ausdrücke
Ein regulärer Ausdruck stellt eine Sprache wie folgt dar:
- für alle
Beispiele
a→ Einfaches Symbol:a1x gematched(a|b)→aoderbwird 1x gematchedab→abwird 1x gematcheda*→awird 0-mal bis ∞-mal gematcheda+→awird 1-mal bis ∞-mal gematched(a|b)*→aoderbwird 0-mal bis ∞-mal gematched (jegliche Kombination ausaundb, da sich der Kleene Stern auf die Klammer bezieht)ab*→awird 1x gematched,bwird 0-mal bis ∞-mal gematched(ab)→abwird 1-mal bis ∞-mal gematched (abababab...)aa* | bb*→ Erst wird ein einzelnesagematched, dann 0 bis ∞-vielea’s oder einb, dann 0 bis ∞-vieleb’s
Experimentieren mit regulären Ausdrücken
Auf der Seite regex101.com kann man gut mit regulären Ausdrücken experimentieren. Mithilfe der Seite können Texte auf reguläre Ausdrücke überprüft werden!
Reguläre Ausdrücke und endliche Automaten
Zu jedem regulären Ausdruck gibt es einen endlichen Automaten, den man aus dem regulären Ausdruck hinaus erschließen kann.
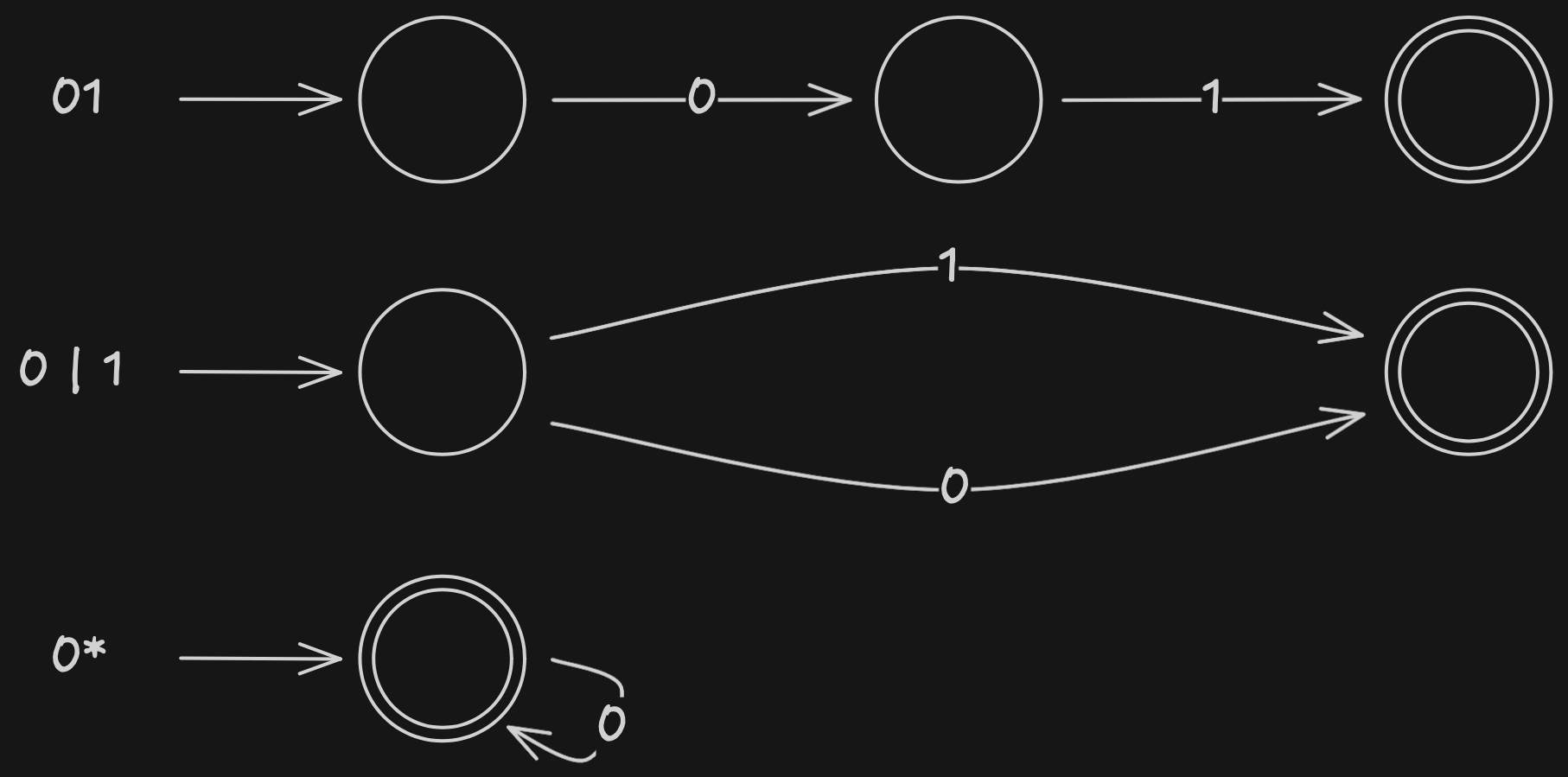
Es ist auch möglich, die Automaten zwei regulärer Ausdrücke zu verknüpfen. Formell wird dies mit dem leeren Wort gemacht:

Das leere Zeichen kann dann in einem zweiten Schritt entfernt werden:
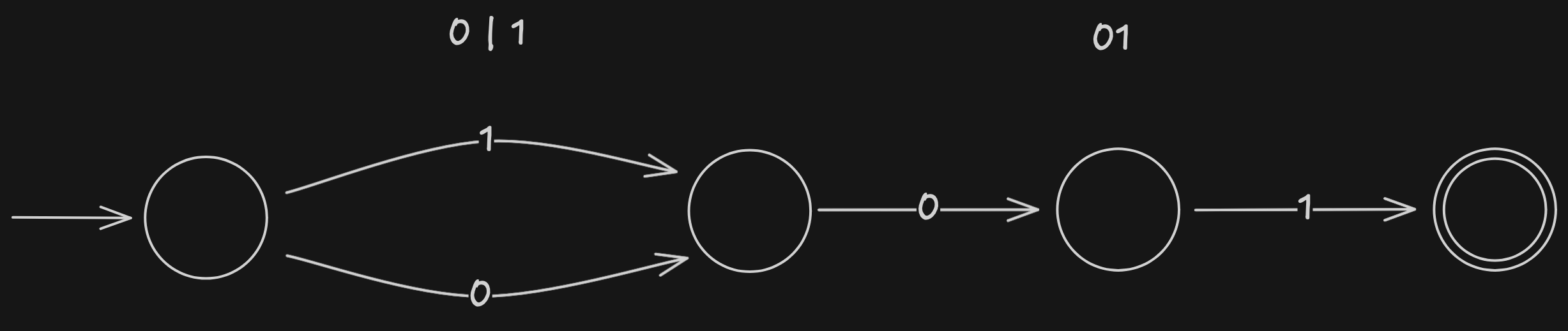
Beim Konstruieren dieser Automaten ist es wichtig, darauf zu achten, dass leere Wörter immer eliminiert werden.
Syntaxdiagramme
Ein regulärer Ausdruck lässt sich mit einem Syntaxdiagramm graphisch darstellen:
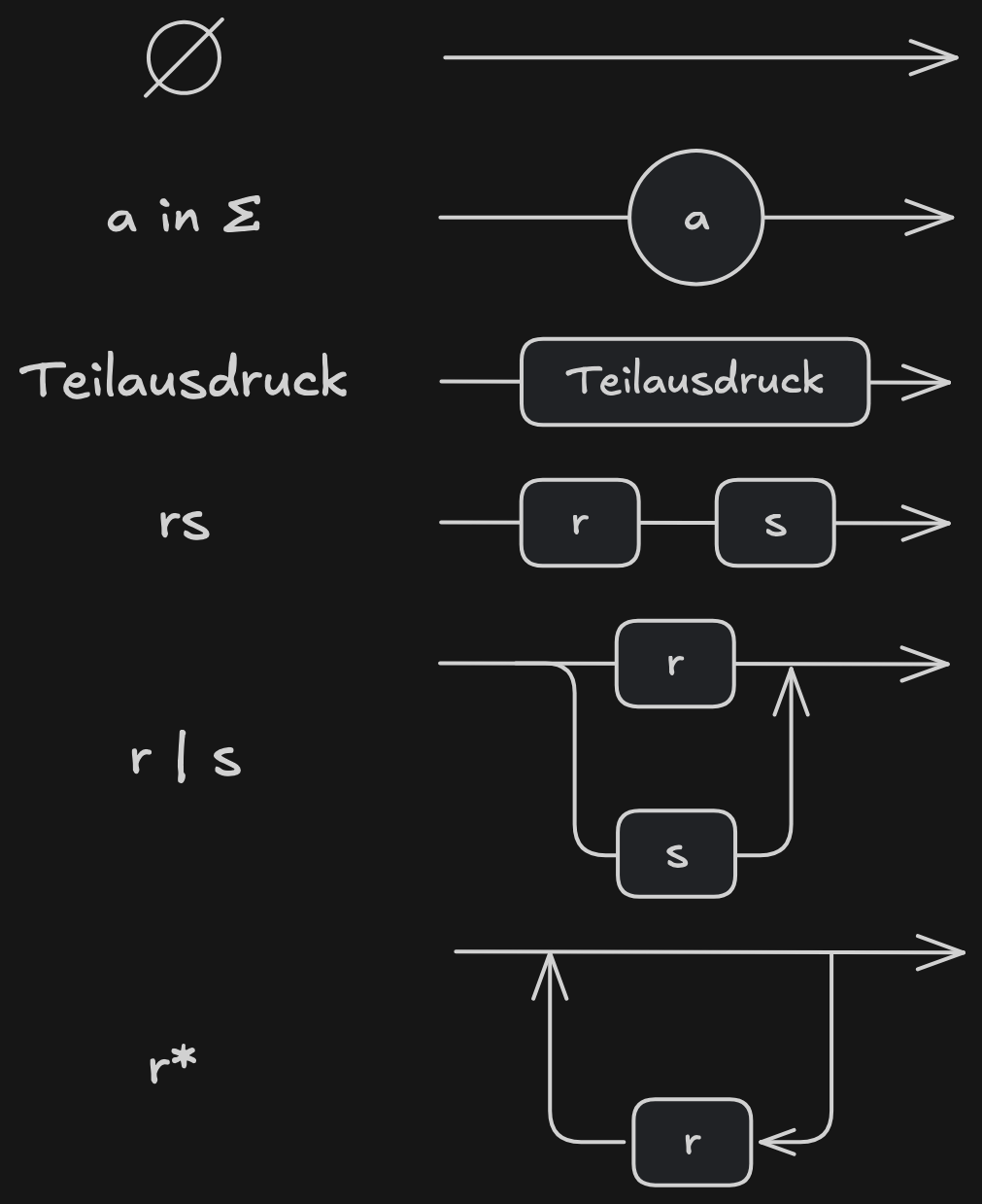
Minimierung endlicher Automaten
Zum Minimieren von EAs kann folgender Algorithmus verwendet werden:
- Stelle eine Tabelle aller Zustandspaare von auf, mit ungleich
- Markiere alle Paare mit genau einem Endzustand
- Für jedes unmarkierte Paar , teste für jedes Symbol ob markiert
- Falls ja, markiere auch
- Wiederhole 3. bis sich keine Änderung mehr ergibt
- Verschmelze alle unmarkierten Zustandspaare zu einem neuen Zustand
Zuerst stellt man eine Tabelle auf, in der Angekreuzt wird, von welchem Zustand man welchen anderen Zustand erreichen kann. In den Zeilen wird der Startzustand weggelassen, in den Spalten der Endzustand:
| Z0 | Z1 | Z2 | Z3 | Z4 | |
|---|---|---|---|---|---|
| Z0 | ------ | ------ | ------ | ------ | ------ |
| Z1 | ------ | ------ | ------ | ------ | |
| Z2 | ------ | ------ | ------ | ||
| Z3 | ------ | ------ | |||
| Z4 | ------ |
Dann werden alle Paare, bei denen einer der beiden ein akzeptierender Endzustand ist, markiert:
| Z0 | Z1 | Z2 | Z3 | Z4 | |
|---|---|---|---|---|---|
| Z0 | ------ | ------ | ------ | ------ | ------ |
| Z1 | ------ | ------ | ------ | ------ | |
| Z2 | ------ | ------ | ------ | ||
| Z3 | ------ | ------ | |||
| Z4 | x | x | x | x | ------ |
Als nächstes wird überprüft, was passiert, wenn bei jedem Zustand eines unmarkierten Zustandspaares die selbe Eingabe gemacht wird. Man erhält ein neues Paar . Wenn das neue Paar bereits markiert ist, bedeutet das, dass nach Lesen des Symbols a die Zustände in einen bereits bekannt unterschiedlichen Zustand übergehen. Man markiert .
| Z0 | Z1 | Z2 | Z3 | Z4 | |
|---|---|---|---|---|---|
| Z0 | ------ | ------ | ------ | ------ | ------ |
| Z1 | x | ------ | ------ | ------ | ------ |
| Z2 | x | ------ | ------ | ------ | |
| Z3 | x | x | ------ | ------ | |
| Z4 | x | x | x | x | ------ |
Nachdem dies für den Rest der Tabelle wiederholt wurde, sind alle markierten Paare sicher verschieden. Alle unmarkierten Paare sind äquivalent und können kombiniert werden. Hier wird aus ein neuer Zustand und aus wird , da beide bei den selben Eingaben gleich reagieren. Visuell kann man sich Vorstellen, dass die Kreise “übereinander geschoben werden”, da die Pfeile zu den jeweiligen Kreisen des Automaten für den neuen Kreis einfach kombiniert werden.
Nichtdeterministische endliche Automaten (NEA)
Ein nichtdeterministischer endlicher Automat (NEA) ist ein Automat, bei dem aus einem Anfangszustand mit einer Eingabe mehrere Zustände erreicht werden können. Es ist also nicht eindeutig festgelegt, in welchem der passenden Zustände man landet. Ein NEA kann sozusagen also “hellsehen”, d.h. er weiß immer, welcher der möglichen Wege zu wählen ist (eigentlich macht das ein Backtracking-Algorithmus, aber egal).
Ein NEA wird formell definiert durch
wobei:
- die endliche Menge von Zuständen darstellt
- für das endliche Eingabealphabet steht
- die Übergangsrelation symbolisiert
- der Anfangszustand ist
- die Menge der akzeptierenden Endzustände verkörpert
Umformung NEA zu DEA
Jeder NEA lässt sich durch die Potenzmengenkonstruktion auch in einen DEA umstrukturieren. Dabei wird angenommen, dass ein Zustand des DEA alle Zustände, in denen sich der NEA nach einer Eingabe befinden könnte, kodiert. Die Zustandsmenge des DEA ist dabei Teil der Potenzmenge der Zustandsmenge des NEA - daher der Name. (Problem: DEAs, die auf diese Art konstruiert werden, werden meist sehr groß.)
Bei der Potenzmengenkonstruktion wird ein DEA
zu einem NEA
aufgebaut:
- Die Zustandsmenge und die Menge der akzeptierenden Endzustände werden als leere Mengen gewählt.
- . Füge zu hinzu.
- Konstruiere den Folgezustand für alle aus und für alle aus als Menge aller Zustände, die der NEA in dieser Situation erreichen könnte.
- Füge zu hinzu, falls noch nicht enthalten
- Ergänze die Übergangsfunktion
- Wiederhole Schritt 3 bis 5, bis sich und nicht mehr ändern
- Wähle die Menge der Finalzustände als diejenige Teilmenge von , deren Zustände einen Finalzustand aus enthalten.
⇒ Der DEA kann am ende bis zu Zustände haben!
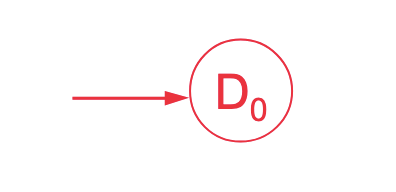
Beispiel
NEA:
Als erstes wird für der Startzustand als übernommen:
Bei Eingabe zum Zustand würde der NEA zwischen und entscheiden müssen. Beim DEA wird dafür ein neuer Zustand erstellt:
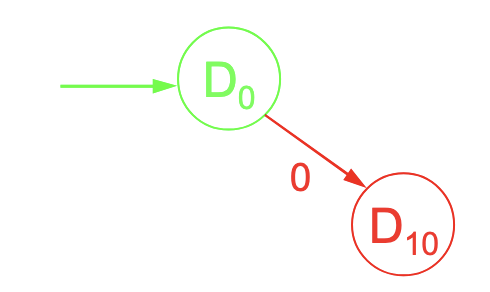
Bei Eingabe hingegen wechselt der NEA zu . Dieses Verhalten wird als übernommen:
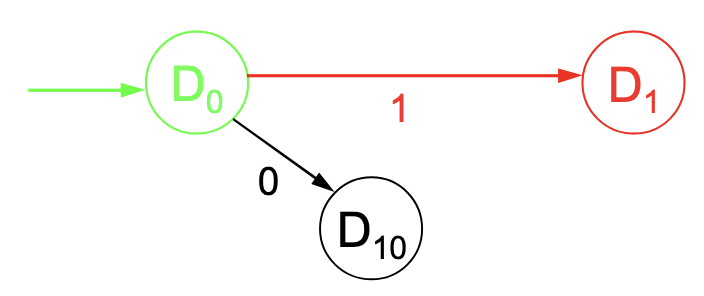
Nun ist jedoch bei die Eingabe einer nicht Eindeutig, deswegen benötigen wir eine weitere Schleife (schließlich wissen wir nicht, ob wir uns in oder befinden, solange wir in sind):
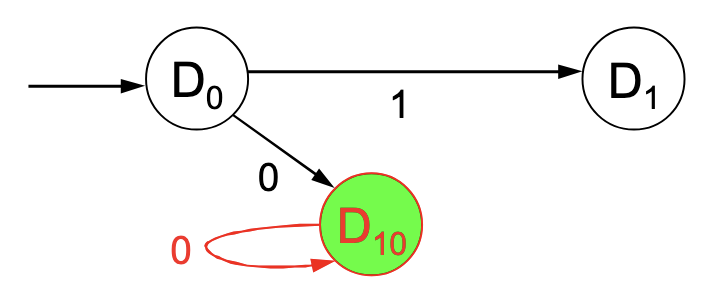
Zu guter Letzt wird die Eingabe im “Quantenzustand” eingebaut:
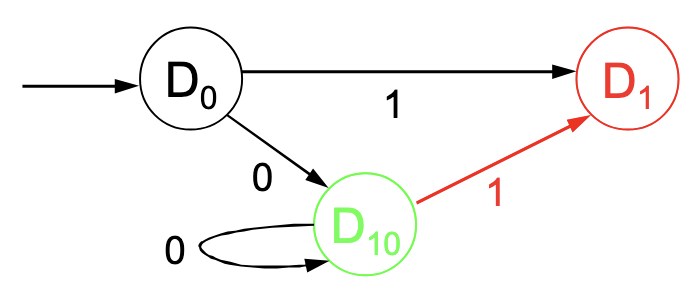
Da nun alle Übergange eingebaut sind, können die Endzustände gewählt werden:
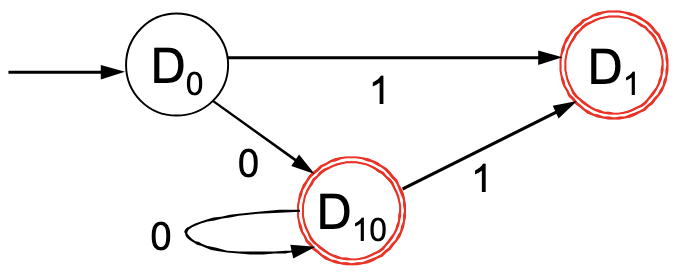
In tabellarischer Darstellung sieht dieser Algorithmus folgendermaßen aus:
| Von ( = / ) | NEA | DEA |
|---|---|---|
| Start | ||
| = / | / | |
| = / | ||
| / | / | |
| / |
Regulärer Ausdruck aus NEA
Mit der Zustandselimination kann aus einem NEA ein regulärer Ausdruck erzeugt werden. Die Zustandselimination verwendet sog. verallgemeinerte NEAs (VNEAs), um den regulären Ausdrück möglichst einfach zu erreichen (links ist ein NEA, rechts ein VNEA):
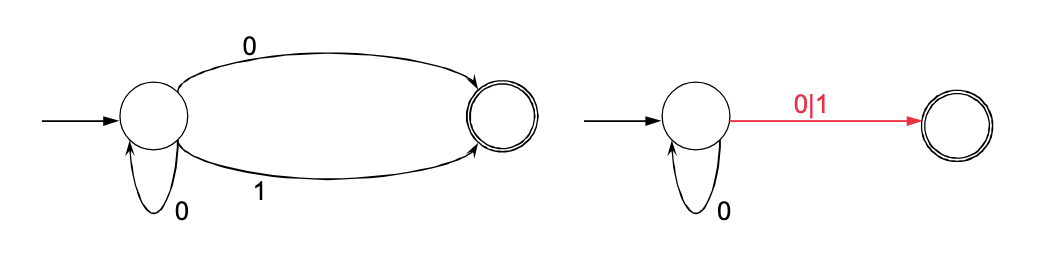
Bei der Zustandselimination wird folgendes gemacht:
- Wandle den NEA in einen VNEA um
- Wiederhole für alle Endzustände :
- Eliminiere (iterativ, also nacheinander, nicht gleichzeitig!) alle Zustände außer dem Startzustand und .
- Bilde einen regulären Ausdruck aus dem finalen Automaten
- Vereinige die Ausdrücke für alle Endzustände q
- Bilde die Summe aller entstandenen regulären Ausdrücke
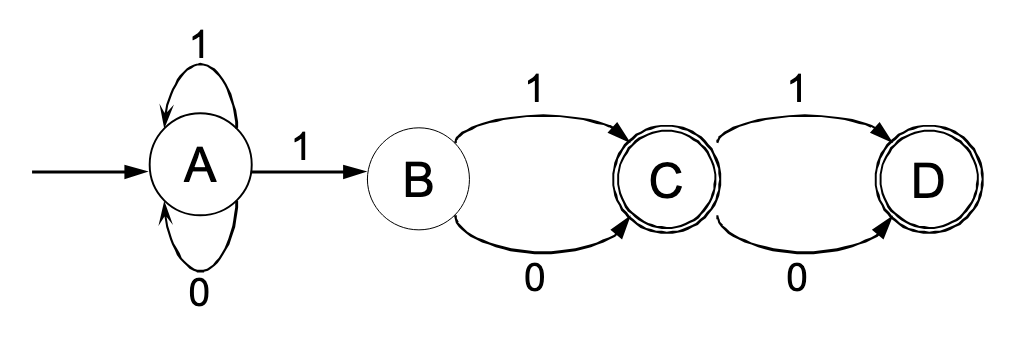
Beispiel
NEA:
VNEA:
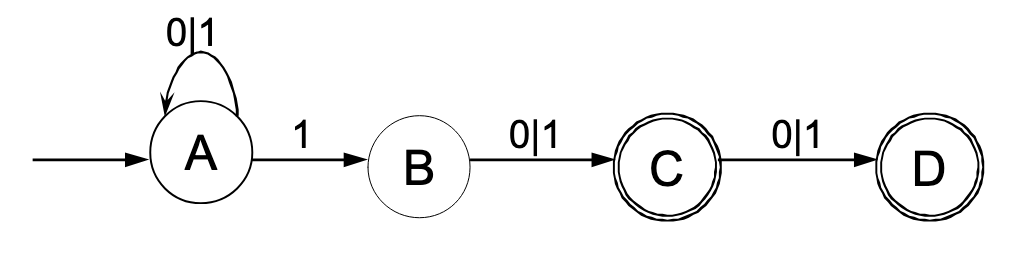
1. Elimination für Endzustand C & D:
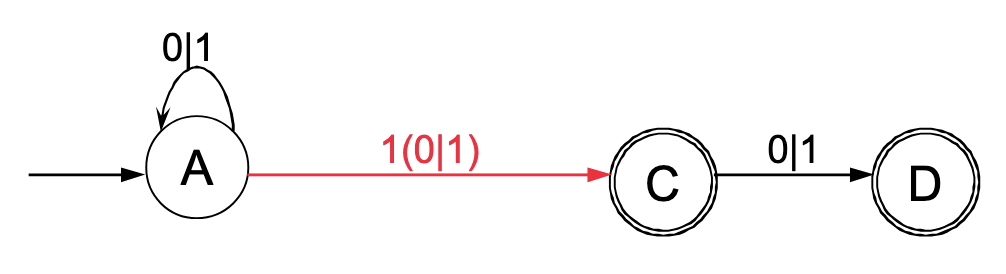
2. Elimination für Endzustand C:

2. Elimination für Endzustand D:
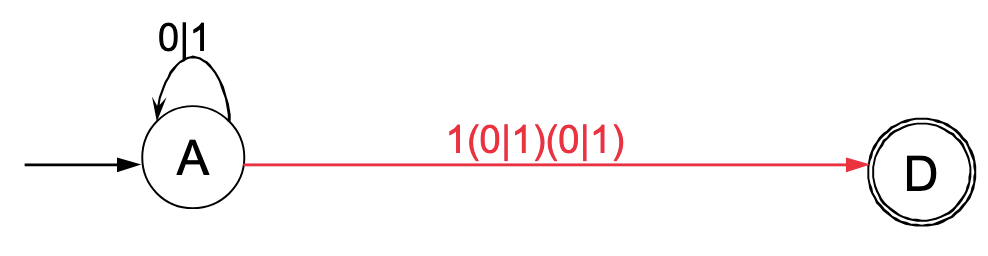
Kombination:
- Endzustand C:
(0|1)*1(0|1) - Endzustand D:
(0|1)*1(0|1)(0|1) - Kombiniert:
(0|1)*1(0|1)|(0|1)*1(0|1)(0|1) - Optimiert:
(0|1)*1(0|1)(ε|(0|1))
Kellerautomaten
Ein EA kann sich nur bestimmt viele Zustände “merken”. Eine Sprache, bei der man Zählen muss und bei der die Obergrenze nicht bekannt ist, lässt sich also nicht darstellen. Ein Kellerautomat ist ein Automat, der Zugriff auf einen “Kellerspeicher” (Stack) hat. Er kann also Dinge speichern. Der Stack ist zudem theoretisch unendlich, was bedeutet, dass er z.B. zum Zählen verwendet werden kann.
Ein Kellerautomat ist definiert als:
Symbole:
- : Endliche Menge von Zuständen
- : Endliches Eingabealphabet
- : Endliches Kelleralphabet
- : Übergangsrelation
- : Anfangszustand
- : Keller-Bottomsymbol
- : Endzustandsmenge
⇒ Ein Standard-Kellerautomat ist nichtdeterministisch! Nur wenn die Übergangsrelation eindeutig ist spricht man von einem deterministischen Kellerautomaten (DKA/DPDA). Im Gegensatz zu normalen endlichen Automaten sind ein KA und DKA nicht äquivalent, d.h. der DKA erkennt nur eine echte Teilmenge der vom KA erkannten Sprachen.
Kellerautomaten können auch ohne Endzustandsmenge () definiert werden. Dann akzeptiert der KA eine Eingabe, falls nach der Abarbeitung der Eingabe der Keller leer ist. Wenn der KA nichtdeterministisch ist, sind die beiden Varianten (mit und ohne Endzustandsmenge) äquivalent. Zu jedem KA existiert außerdem ein äquivalenter KA ohne ε-Übergänge.
Zustandsüberführung
Die Zustandsüberführung bei Kellerautomaten funktionieren so:
Bedeutet:
- Wenn sich der Kellerautomat gerade im Zustand befindet,
- gerade das Zeichen liest und
- das oberste Kellersymbol ist,
- dann kann der Kellerautomat in den Zustand wechseln
- und dabei durch das Wort ersetzen
Dies lässt sich am einfachsten Schreiben als:
Bedeutung der Symbole:
- : Aktueller Zustand
- : Gelesenes Zeichen
- : Oberstes Kellersymbol
- : Neuer Zustand
- : Neues Wort, wodurch überschrieben wird
Konfiguration
Jeder Kellerautomat benötigt außerdem eine Konfiguration , die den aktuellen Zustand , das noch zu verarbeitende Suffix des Eingabewortes und den aktuellen Kellerinhalt beinhaltet:
Konfigurationsübergänge
Ein Konfigurationsübergang ist festgelegt durch die Relation . Wenn also eine Zustandsüberführung Teil der Übergangsrelation ist, ist automatisch ein valider Übergang, durch den das oberste Kellersymbol () gelöscht und durch ein neues Wort ersetzt wird.
Akzeptierte Sprachen
Eine von einem Kellerautomat akzeptierte Sprache ist definiert als:
Erklärung der Symbole:
- : Ein Eingabewort muss in der Summe aller Wörter enthalten sein.
- : Es muss möglich sein, vom Startzustand mit dem Eingabewort bei einem leeren Keller () auf einen Endzustand zu gelangen, bei dem das Eingabewort gänzlich gelesen wurde () und etwas () im Keller steht.
- : Der Endzustand muss in der Zustandsmenge des Automaten enthalten sein
- : Das Wort im Keller muss im Kelleralphabet enthalten sein
Falls der Automat auch bei leerem Keller akzeptieren soll, kann die Sprache definiert werden als:
⇒ Der Zustand, der nach Einlesen des Wortes erreicht ist, muss Teil der definierten Zustände des Kellerautomaten sein.
Übergangsrelationen
Eine einfachere Schreibweise für die Übergangsrelationen des Kellerautomaten lautet:
- Aktueller Zustand: Der aktuelle Zustand, in dem sich der Kellerautomat befindet
- Symbol: Das eingelesene Symbol
- Kellersymbol 0: Das oberste Kellersymbol
- Neuer Zustand: Der Zustand, in den der Automat wechseln soll
- Input für Keller: Was anstelle von Kellersymbol 0 geschrieben werden soll (Kellersymbol 0 wird beim Lesen entfernt)
⇒ Wenn sich der Kellerautomat im aktuellen Zustand befindet, Symbol eingelesen wird und das oberste Kellersymbol gleich Kellersymbol 0 ist, soll der Automat in den neuen Zustand übergehen und den neuen Input in den Stack schreiben.
Kontextfreie Sprachen
Mit einer kontextfreien Sprache lassen sich die regulären Sprachen (aber auch weitere Sprachen) ausdrücken. Eine Kontextfreie Sprache kann z.B. durch eine kontextfreie Grammatik beschrieben werden.
Grammatik
Eine Grammatik ist ein Tupel :
- : Terminal-Alphabet
- : Nonterminal-Alphabet (Variablen)
- : Produktionenmenge (Regelmenge)
- : Startsymbol
Großbuchstaben sind Variablen, S ist (meist) das Startsymbol. Kleinbuchstaben sind Terminale. Die Großbuchstaben , und sind Symbole, die als Terminale und Variablen genutzt werden können.
Die Kleinbuchstaben bis sind Zeichenketten aus anderen Terminalen und die griechischen Kleinbuchstaben , , , … sind Zeichenketten aus Variablen und Terminalen (beide sind Variablen für größere Zeichenketten).
Für die Darstellung einer Grammatik genügt die Angabe der Produktionen, da die Konventionen aus den Variablen, Terminalen und dem Startsymbol hergeleitet werden können.
Außerdem können Produktionen zusammengefasst werden:
kann mit dem ODER-Operator geschrieben werden als
Eine Grammatik heißt kontextfrei, falls für ihre Regelmenge gilt:
d.h. falls jede Regel die Form hat.
Kontextfreie Sprache
Eine Sprache heißt kontextfrei, wenn es eine kontextfreie Grammatik mit gibt (Solche Sprachen werden auch Typ-2-Sprachen genannt).
Ableitung
Eine Ableitung beschreibt, wie man vom Startsymbol zu einem Wort der Sprache kommt. Ein Ableitungsschritt () ist hierbei die Ersetzung eines Nichtterminals durch eines oder mehrere (Nicht-) Terminale. Die Ableitung endet, wenn keine Nichtterminale mehr auftreten.
Transitive Hülle
Die transitive Hülle des Ableitungsschritts bezeichnet die gesamte Ableitung bis zu einem Wort:
Es gilt also:
⇒ Für jedes Wort der Grammatik muss man aus einem Zustand irgendwie das Wort erreichen können.
Links-/Rechtsableitung
Eine Links- bzw. Rechtsableitung beschreibt eine Ableitung, bei der immer nur das am weitesten links/rechts stehende Nichtterminal ersetzt wird.
Linksableitung:
Rechtsableitung:
Ableitungsbäume
Zu einer kontextfreien Grammatik kann ein Baum erstellt werden, der die Ableitung symbolisiert. Damit ein Baum als Ableitungsbaum bezeichnet werden darf, müssen folgende Bedingungen erfüllt sein:
- Die Wurzel muss mit markiert sein
- Jeder Knoten ist mit (einem (Nicht-) Terminal) markiert
- Jeder innere Knoten ist mit einem (einem Nichtterminal) markiert
- Wenn ein innerer Knoten mit (einem Nichtterminal) markiert ist und seine Nachfolger von links nach rechts mit (einem Terminal), dann muss sein.
- Wenn ein Knoten mit markiert ist, ist ein Blatt und der einzige Sohn seines Vaters
Beispiel:
Ableitungsbaum für die Linksableitung
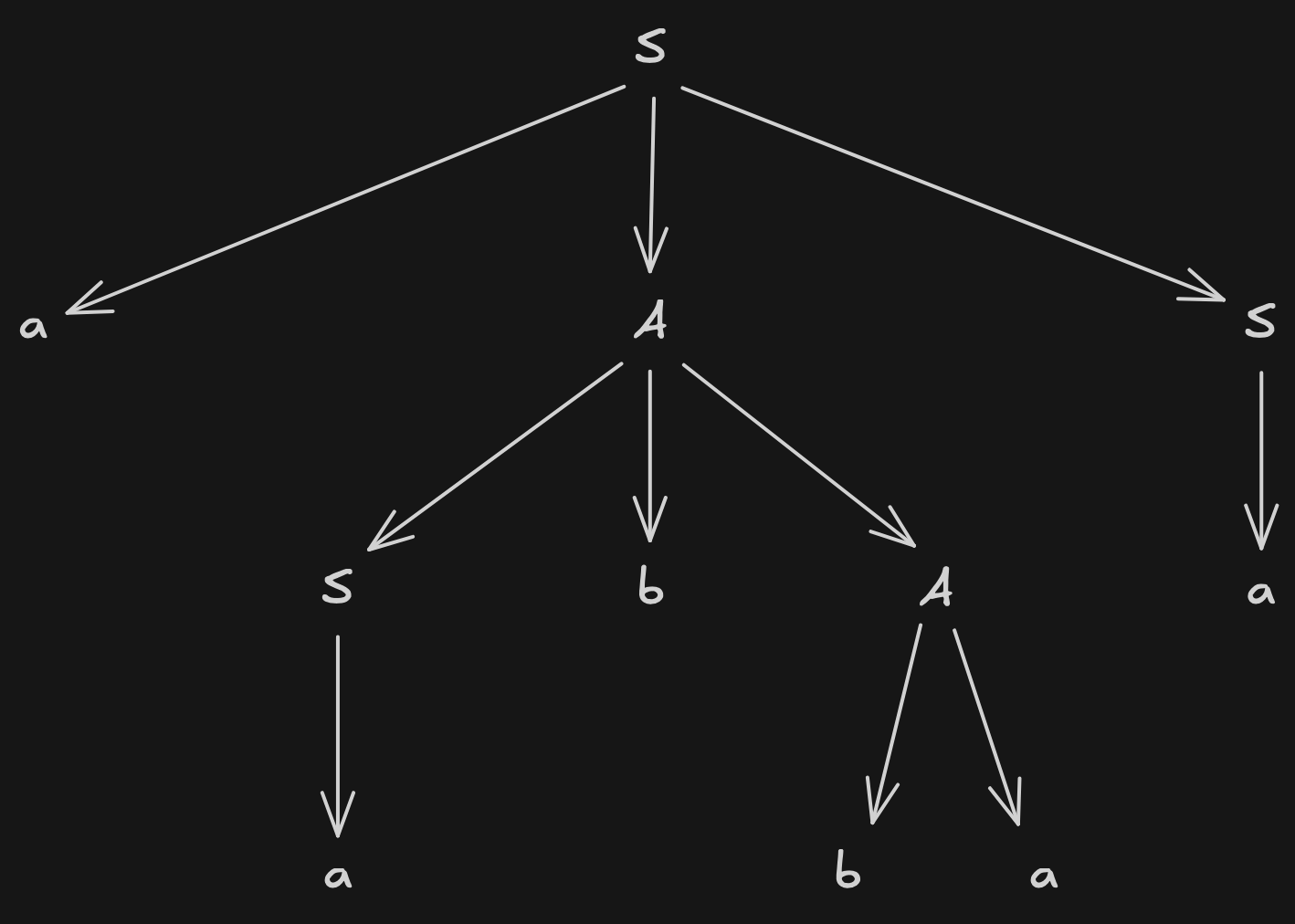
Ein Ableitungsbaum ist eine natürliche Beschreibung für die Ableitung einer bestimmten Satzform der Grammatik G, die man erhält, wenn man die Markierungen aller Blätter von links nach rechts liest. Diese Zeichenkette wird auch Front des Ableitungsbaumes genannt:
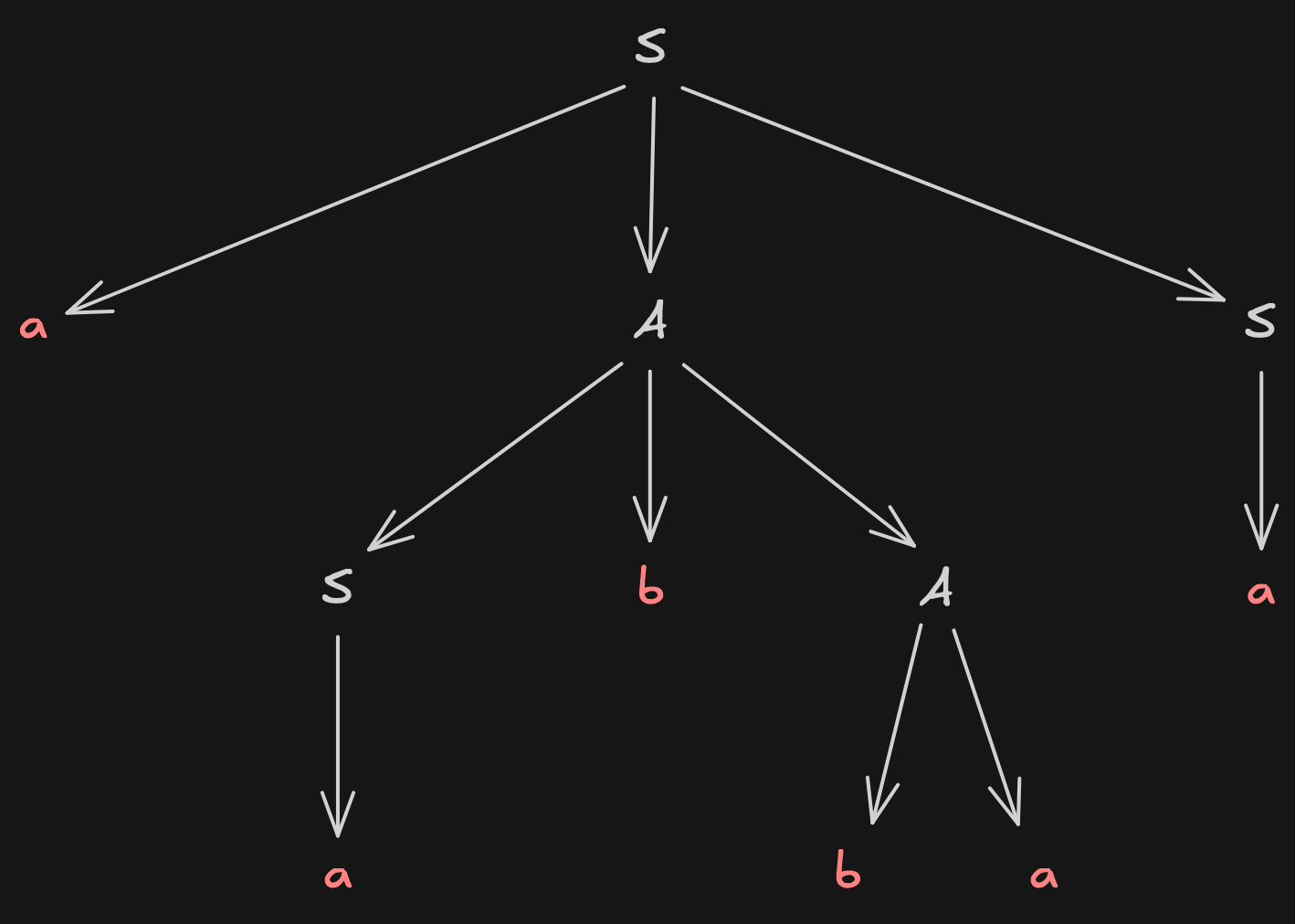
Achtung!
Zu einer Satzform können mehrere Ableitungsbäume existieren.
Mehrdeutigkeit
Eine kontextfreie Grammatik heißt mehrdeutig, falls es für mindestens ein Wort zwei (oder mehr) verschiedene Ableitungsbäume gibt, oder falls mindestens ein Wort mehr als eine Links-/Rechtsableitung hat. Eine kontextfreie Sprache, die für jede kontextfreie Grammatik.
Vereinfachungen
Ziel bei der Vereinfachung ist, das Format der Produktionen einzuschränken, ohne deren Fähigkeit zur Erzeugung von Sprachen zu beschneiden. Eine kontextfreie Grammatik lässt sich durch folgende Maßnahmen vereinfachen:
- Eliminierung von ε-Regeln: Es gibt keine Produktionen der Form wenn
- Eliminieren nutzloser Symbole: Jede Variable und jedes Terminal von erscheint in der Ableitung mindestens eines Wortes aus
- Eliminieren von Kettenregeln: Es gibt keine Produktionen der Form , wenn und Variablen sind
Eliminieren von ε-Regeln
- Bestimme alle Nichtterminale, die in ein ε umgewandelt werden können:
- Bestimme alle Nichtterminale, aus denen das leere Wort ableitbar ist:
- Für jede Regel, deren Rechte Seite ein Nichtterminal aus enthält, fügen wir eine Regel ohne dieses Nichtterminal hinzu.
- Eliminiere alle ε-Regeln (entferne das ε aus allen Umformungen und entferne die Umformung selbst, falls das ε nicht verodert ist)
Beispiel:
Hier führt zu einem leeren Wort, also “markieren” wir es im 1. Schritt. Da sich aus ableiten lässt, markieren wir auch dies. In Schritt 3 wird umgeformt, da wir das in der Ableitung dort markiert haben:
Im letzten Schritt entfernen wir das ε aus der Ableitung von :
Eliminieren nutzloser Symbole
Beim Eliminieren von nutzlosen Symbolen wird darauf geachtet, welche Symbole nützlich für die Grammatik sind. Ein Symbol heißt nützlich, wenn mit seiner Hilfe mindestens ein Terminalwort erzeugt werden kann, also wenn gilt:
mit und .
Beim Eliminieren von nützlichen Symbolen wird also darauf geachtet, dass zwei Aspekte der Nützlichkeit für jedes Symbol gegeben sind:
- Aus muss eine Terminalzeichenkette ableitbar sein (Lemma 1)
- muss Teil einer Zeichenkette sein, die aus ableitbar ist (Lemma 2)
Lemma 1 beschäftigt sich mit der Erreichbarkeit von Symbolen. Ein Symbol muss erreichbar sein, also vom Startsymbol aus in einer Folge von Produktionen irgendwann erzeugt werden. Bei Lemma 1 werden alle Symbole, die niemals vom Startsymbol aus erreicht werden können, eliminiert. Der Algorithmus hierzu sieht so aus:
- Merke dir alle Nichtterminale, die per Ableitung in ein Terminal verwandelt werden können ( ⇒ A muss ein Nichtterminal produzieren, was in der Menge aller Wörter steht)
- Prüfe, welche Ableitungen zu den gemerkten Nichtterminalen führen, und markiere diese, bis alle Ableitungen durchlaufen sind. Sobald alle anderen Ableitungen angeschaut und markiert sind, entferne alle nicht markierten Ableitungen.
Lemma 2 hingegen eliminiert nicht erzeugende Symbole. Ein Symbol ist erzeugend, wenn es ein Wort bestehend aus nur Terminalsymbolen ableiten kann. Alle Symbole, die kein terminales Wort erzeugen können, sind ebenfalls nutzlos.
- Starte bei und durchlaufe alle möglichen Ableitungen, um zu sehen, welche Nichtterminale erreicht werden können. Entferne alle Ableitungen, die nicht erreicht werden können.
Eliminieren von Kettenregeln
Kettenregeln sind Regeln mit folgender Form:
Sie tragen zur Erzeugung eines Wortes nichts bei. Kettenregeln können mit 3 Schritten eliminiert werden:
- Entfernen von Zyklen: Gibt es Nichtterminale, die einen Zyklus erzeugen (z.B. ), fügen wir ein neues Nichtterminal hinzu und ersetzen alle durch .
- Umnummerierung: hat nun Elemente. Wir bezeichen diese mit , so dass gilt: Wenn , dann ist
- Ersetzen von Kettenregeln: Wenn noch Regeln wie dann kann jede Regel ersetzt werden durch
Im folgenden Beispiel gibt es keine Zyklen, daher müssen diese nicht entfernt werden (Lemma 1 nicht zutrefflich). Auch Lemma 2 ist nicht zutrefflich, da alle Nichtterminale von aus erreicht werden können.
Allerdings existieren Kettenregeln, die entfernt werden können: ist equivalent zu . Außerdem kann vereinfacht werden zu .
Damit ist die Vereinfachung abgeschlossen.
Chomsky-Normalform (CNF)
Eine kontextfreie Grammatik ist in CNF, wenn alle ihre Produktionen eine der folgenden Formen haben:
- (nur vorhanden, wenn das leere Wort erzeugt)
(mit und )
⇒ Zu jeder kontextfreien Sprache lässt sich eine Grammatik in CNF angeben, so dass ist.
Zum Erzeugen der CNF einer Grammatik muss die Grammatik maximal vereinfacht vorliegen. Man beachte die Produktionen :
- Wenn vorhanden ist: Ersetze durch , füge neue Produktion hinzu, ersetze alle anderen durch .
- Wenn kein vorhanden ist: Betrachte die Produktion und ersetze dies durch die Produktionen .
Wortproblem & CYK-Algorithmus
Wenn eine kontextfreie Grammatik in der CNF sowie ein Wort gegeben sind, stellt sich die Frage, ob das Wort Teil der Sprache ist (). Dies kann mit dem Cocke-Younger-Kasami-Algorithmus (CYK) beantwortet werden.
Die Idee lautet wiefolgt: Für jedes Teilwort der Sprache wird die Menge der Nichtterminale berechnet, die benötigt werden, um das Wort zu erzeugen. Man dringt hierbei von kleineren zu immer größeren Teilwörtern vor. Am Einfachsten ist dies Tabellarisch zu erreichen.
Beispiel
- Gesuchtes Wort
- Produktionen:
Es wird eine Tabelle mit Zeilen und Spalten aufgestellt, wobei :
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | ------ | |||||
| 3 | ------ | ------ | ||||
| 4 | ------ | ------ | ------ | |||
| 5 | ------ | ------ | ------ | ------ | ||
| 6 | ------ | ------ | ------ | ------ | ------ |
Entlang der Hauptdiagonalen werden dann die Terminale von eingetragen:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | b | |||||
| 2 | ------ | b | ||||
| 3 | ------ | ------ | a | |||
| 4 | ------ | ------ | ------ | b | ||
| 5 | ------ | ------ | ------ | ------ | a | |
| 6 | ------ | ------ | ------ | ------ | ------ | a |
Dann werden die Terminale durch die möglichen Nichtterminale, durch die sie direkt erzeugt werden können ersetzt:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | B | |||||
| 2 | ------ | B | ||||
| 3 | ------ | ------ | A, C | |||
| 4 | ------ | ------ | ------ | B | ||
| 5 | ------ | ------ | ------ | ------ | A, C | |
| 6 | ------ | ------ | ------ | ------ | ------ | A, C |
Hier beginnt der Algorithmus. Zuerst schauen wir uns an. Da es keine Produktion gibt, die erzeugt, tragen wir ”{}” ein:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | B | {} | ||||
| 2 | ------ | B | ||||
| 3 | ------ | ------ | A, C | |||
| 4 | ------ | ------ | ------ | B | ||
| 5 | ------ | ------ | ------ | ------ | A, C | |
| 6 | ------ | ------ | ------ | ------ | ------ | A, C |
Bei hingegen gibt es Produktionen, die entweder oder erzeugen, weshalb wir die Terminale für die Produktionen () dort eintragen:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | B | {} | ||||
| 2 | ------ | B | S, A | |||
| 3 | ------ | ------ | A, C | |||
| 4 | ------ | ------ | ------ | B | ||
| 5 | ------ | ------ | ------ | ------ | A, C | |
| 6 | ------ | ------ | ------ | ------ | ------ | A, C |
Weiter geht es danach mit , , , , , usw. Nachdem die ganze Tabelle ausgefüllt wurde, sieht sie wie folgt aus:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | B | {} | A | S, C | B | A, S |
| 2 | ------ | B | S, A | S, C | B | A, S |
| 3 | ------ | ------ | A, C | S, C | B | S, A |
| 4 | ------ | ------ | ------ | B | S, A | {} |
| 5 | ------ | ------ | ------ | ------ | A, C | B |
| 6 | ------ | ------ | ------ | ------ | ------ | A, C |
Nachdem die Tabelle gefüllt ist, muss in der oberen rechten Ecke das Startsymbol zu finden sein. Falls es vorhanden ist, ist das Wort in der Sprache enthalten.
Reguläre Grammatiken
Bisher wurden reguläre Sprachen und kontextfreie Sprachen behandelt. Zur Wiederholung, eine reguläre Sprache ist beschrieben durch einen regulären Ausdruck oder ein Syntaxdiagramm und wird akzeptiert durch endliche Automaten. Eine kontextfreie Sprache hingegen wird durch eine kontextfreie Grammatik beschrieben und von (nichtdeterministischen) Kellerautomaten akzeptiert.
Reguläre Sprachen können aber auch durch eine eigene Grammatik beschrieben werden.
⇒ Eine Sprache ist genau dann regulär, wenn sie durch eine reguläre Grammatik erzeugt wird.
Links-/Rechtslinearität
Eine kontextfreie Grammatik, deren Produktionen alle die Form
besitzen, heißt linkslinear. Genauso heißt eine kontextfreie Grammatik, deren Produktionen alle die Form
besitzen rechtslinear.
⇒ ==Eine Grammatik heißt regulär, wenn sie rechtslinear oder linkslinear ist.==
Grenzen kontextfreier Sprachen
(TODO)
Linear bandbeschränkte Automaten (LBA)
Reguläre Sprachen haben ebenfalls Grenzen. Eine Sprache bei der man “zählen” muss und bei der die Obergrenze nicht bekannt ist, lässt sich nicht als reguläre Ausdrücke darstellen. Die Sprache
beispielsweise kann nicht durch eine kontextfreie Grammatik erzeugt werden. Das Hauptproblem liegt darin, dass bei den Kellerautomaten und bei kontextfreien Sprachen das Lesen aus dem Stack das gelesene Element zerstört. Es ist also nicht möglich, eine Information vom Stack zu lesen und für später aufzuheben.
Die Lösung hierfür sind linear bandbeschränkte Automaten (LBAs). Anstelle des Stacks verwenden sie ein “Band” als Speichermedium, ähnlich einem Magnetband. Das Band wird von einem endlichen Automaten mit “Schreib-Lese-Kopf” gelesen und beschrieben. Der Kopf steht immer über einem Feld des Bandes. In einem Schritt:
- liest der Kopf das Symbol auf dem Band,
- schreibt, falls nötig, ein neues Symbol,
- ändert seinen Zustand und
- führt eine Bewegung nach rechts oder links aus
Zu Beginn der Verarbeitung befindet sich die Eingabe auf dem Band selbst. Wie der Name des Automaten vermuten lässt, ist er nach rechts und links beschränkt, seine Länge ist also endlich. Dies wird über Start- und Ende-Zeichen realisiert, die nicht überschrieben werden können. Die formale Definition des Automaten lautet:
Wobei:
- die endliche Menge an Zuständen symbolisiert
- für das endliche Eingabealphabet steht ()
- das Symbol für das endliche Bandalphabet ist
- die Übergangsrelation
- der Anfangszustand ist ()
- das Leerzeichen darstellt ()
- für die linke Endmarkierung steht
- für die rechte Endmarkierung steht
- die Endzustandsmenge verkörpert ( S)
Weitere Symbole, die nicht direkt in der Definition enthalten sind:
- ist das erweiterte Bandalphabet inklusive der Start- und Endsymbole ()
Die Übergangsrelationen bei diesen Automaten werden wie folgt geschrieben:
Eine einzelne Übergangsrelation (hier genannt) aus einem Zustand bei einem gelesenen Zeichen zu Zustand , bei der nichts (das leere Wort) geschrieben wird, und sich der Schreib-Lese-Kopf nach rechts bewegt, sieht also so aus:
Kontextsensitive Sprachen
Der LBA ist equivalent zu einer kontextsensitiven Grammatik. Eine Grammatik gilt als kontextsensitiv, wenn ihre Produktionen die Form
haben: das Nichtterminal kann nur im Kontext ersetzt werden! und dürfen auch leer sein, eine kontextsensitive Grammatik kann also auch kontextfreie Produktionen zulassen.
Eine kontextsensitive Grammatik ist monoton, wenn ihre Produktionen die Form
mit haben.
Sprache
Eine Sprache heißt kontextsensitiv, wenn es eine kontextsensitive Grammatik mit gibt. Kontextsensitive Sprachen (Grammatiken) werden auch Typ-1-Sprachen (-Grammatiken) genannt.
Rekursiv aufzählbare Sprachen
Eine Grammatik ist ein Semi-Thue-System, wenn ihre Produktionen die Form
haben. Die Besonderheit bei einem Semi-Thue-System ist, dass eigentlich keine Unterscheidung zwischen Terminalen und Nichtterminalen existiert. Es werden zwar Nichtterminale verwendet, allerdings sind die Produktionen in keiner Weise eingeschränkt. Rekursiv aufzählbare Sprachen werden von Turing-Maschinen akzeptiert.
Die Turing-Maschine
Die Turing-Maschine hat, genau wie der LBA:
- Ein “Band” als Speichermedium
- Einen Schreib-Lese-Kopf
Der Kopf steht auch hier immer über einem Feld des Bandes und liest in einem Schritt das Symbol, schreibt optionaler ein neues Symbol, ändert seinen Zustand und führt eine Bewegung aus. Auch bei der Turing-Maschine befindet sich die Eingabe zu Beginn bereits auf dem Band. Es gibt jedoch folgende Unterschiede zum LBA:
- Das Band ist nach rechts und links unbeschränkt (es ist unendlich lang)
- Alle Zellen außer der Eingabe sind mit “Blank” gefüllt
Eine Turing-Maschine ist definiert als:
Wobei:
- die endliche Menge an Zuständen symbolisiert
- für das endliche Eingabealphabet steht ()
- das Symbol für das endliche Bandalphabet ist
- die Übergangsrelation
- der Anfangszustand ist ()
- das Leerzeichen darstellt ()
- die Endzustandsmenge verkörpert ( S)
Eine Übergangsrelation (hier ) bei einer Turing-Maschine sieht so aus:
Bei einem Zustand , gelesenem Symbol und einem darauffolgenden Zustandsübergang in , wobei ein geschrieben wird und der Kopf sich nach links bewegt, sieht die Übergangsrelation so aus:
Darstellung
Eine Turing-Maschine kann auch visuell dargestellt werden:
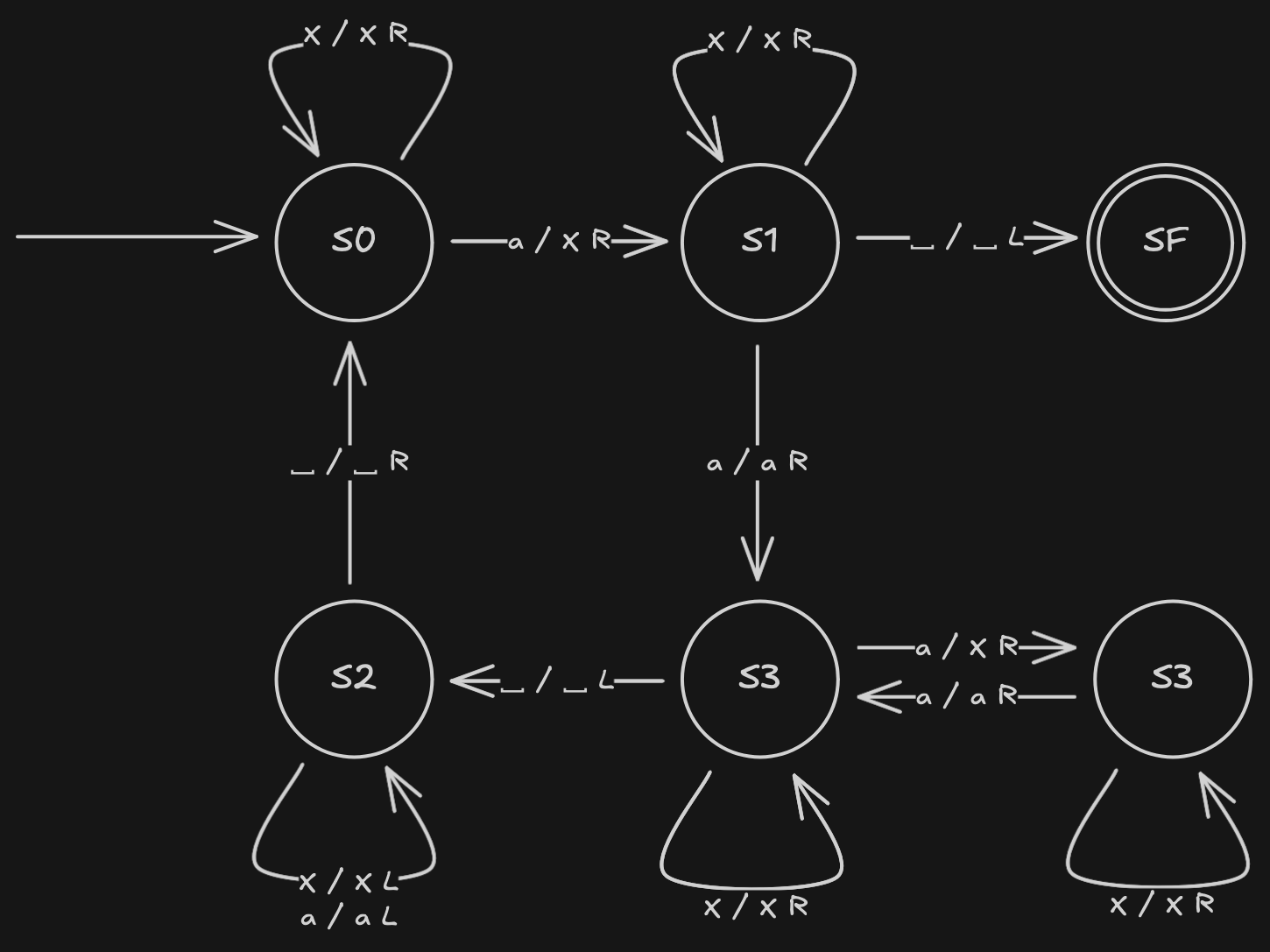
Die Übergange auf den Pfeilen werden gelesen als: .
Erweiterungen von Turing-Maschinen
Das “Programmieren” von Turing-Maschinen ist schwierig, aber es gibt Möglichkeiten, um die TM effizienter zu programmieren. Keine dieser Möglichkeiten erweitert die Fähigkeiten der Turing-Maschine, alle akzeptieren dieselbe Menge von Sprachen wie das Basismodell. Mögliche Erweiterungen für die TM sind:
- Das Speichern einer endlichen Datenmenge im Zustand
- Ein Band aus mehreren Spuren
- Unabhängig bewegbare Schreib-/Leseköpfe auf mehreren Bändern
Nichtdeterministische Turing-Maschinen
Turing-Maschinen können Nichtdeterministisch sein. Wie bei einem NEA können für jeden Zustand und für jedes Bandsymbol mehrere Übergange existieren. Die NTM wählt immer den geeigneten Übergang aus (Hellsehen / Backtracking.)
Berechenbarkeit mit Turing-Maschinen
Mithilfe einer Turing-Maschine kann man Probleme auf ihre Berechenbarkeit untersuchen. Dazu benötigt man eine TM, die in einen akzeptierenden Zustand übergeht und anhält, sobald sie ein Wort als zu einer Sprache zugehörig erkennt. Wenn ein Wort nicht zu einer Sprache gehört, also abgelehnt werden soll, geht sie in einen nicht akzeptierenden Zustand über und hält ebenfalls an. Das Anhalten signalisiert das Ende der Berechnung.
Die von einer TM akzeptieren Sprachen heißen rekursiv aufzählbar. Bei einem Wort, das zur Sprache gehört, hält die TM nach endlich vielen Schritten an. Allerdings gibt es keine Festlegung, was die TM macht, wenn ein Wort nicht zur Sprache gehört. Es gibt also eventuell Wörter, die zur nicht zur Sprache gehören, für die die TM aber auch nie anhält.
Rekursive Sprachen
Eine Sprache heißt rekursiv, wenn für die Turing-Maschine gilt:
- Wenn das Wort zur Sprache gehört, akzeptiert nach endlich vielen Schritten und hält an.
- Wenn das Wort nicht zur Sprache gehört, hält nach endlich vielen Schritten ebenfalls an, geht aber in keinen akzeptierenden Zustand über.
Die rekursiven Sprachen sind eine echte Teilmenge der rekursiv aufzählbaren Sprachen. Eine TM, die eine rekursive Sprache akzeptiert, entspricht der Definition eines Algorithmus, also einer Berechnung, die nach endlich vielen Schritten anhält.
⇒ Rekursive Sprachen Rekursiv aufzählbare Sprachen!
Berechenbarkeit
Bei der Berechenbarkeit geht es um die Frage von Alan Turing, was Computer theoretisch berechnen können, und was nicht. Dabei geht es immer um die Ein- und Ausgabemöglichkeiten der Computer. Eingaben können beispielsweise von Tastatur und Maus kommen, und Ausgaben können über Bildschirme und Lautsprecher gemacht werden. Die Kernkompetenz eines Programms liegt also darin, Eingaben in Ausgaben abzubilden.
Formal kann man diese Abbildung definieren als:
( ist das Eingabealphabet, das Ausgabealphabet.)
Falls die Funktion nicht sämtliche mögliche Eingaben akzeptiert, sondern nur eine Teilmenge davon, spricht man von einer partiellen Funktion:
Wenn eine Eingabe nicht abbildbar ist, schreibt man:
()
Eine partielle Funktion nennt man berechenbar, falls es einen Algorithmus gibt, der diese Funktion berechnet. Wie die Alphabete und dabei tatsächlich aussehen ist eigentlich egal. Man kann sie immer durch ein Binärwort kodieren. Die Art der Kodierung ist nicht vorgeschrieben und kann für jedes Ein- und Ausgabealphabet anders definiert sein.
Algorithmus
Es gibt nicht wirklich einen einzigen Algorithmus zum Lösen solcher Probleme. Vielmehr gilt: Wenn es möglich ist, eine Funktion in irgendeiner Programmiersprache zu programmieren, ist die Funktion sicher berechenbar.
Satz von Cantor
Der Satz von Cantor besagt, dass für jede Menge die Menge ihrer Teilmengen (Die Potenzmenge ) strikt größer ist als selbst ()
Nicht berechenbare Funktionen
Da Programme einen endlichen Quelltext besitzen, muss es (sehr viele) Funktionen geben, die nicht durch ein Programm berechnet werden können. Die Berechenbarkeit ist davon abhängig, was ein Algorithmus kann / darf.
Church’sche These
“Jede Präzisierung des Begriffes Algorithmus führt auf die gleiche Menge berechenbarer Funktionen.”
⇒ Man kann prinzipiell auf jedem Rechner jeden anderen Rechner simulieren. Die Hardware ist nicht entscheidend für die Berechenbarkeit einer Funktion. Die Programmiersprache ist ebenfalls nicht entscheidend.
Halteproblem der TM
Es ist nicht möglich, einen Algorithmus zu definieren, der für jede Turing-Maschine und für jede Eingabe berechnet, ob die Turing-Maschine mit dieser Eingabe anhält.
Fehlend: Stoff von Folien 452 bis 461!
Turing-Maschinen in Binärdarstellung
Eine Turing-Maschine kann in eine Binärzeichenkette umgewandelt werden, indem allen Symbolen, Zuständen und Richtungen eindeutige Binärcodes zugewiesen werden.
Jede Übergangsfunktion wird als Binärfolge kodiert:
⇒ Niemals zwei Einsen hintereinander!
Dann werden alle Übergangscodes durch zwei Einsen zusammengefügt:
kodiert so die Turing-Maschine .
Compilerbau
TODO: Noch nicht in der Vorlesung gehört.
Klausurthemen
- Sprache/Automat in Chomsky-Hierarchie einordnen
- Umwandlung NEA/DEA
- RE → NEA → DEA → RE
- Übergangsdiagramm ⇐> Syntaxdiagramm (Darstellung)
- Sprache (alle Wörter) aus RE/RG erzeugen
- lexikographische Ordnung
- Spache in Automat (dreierrest Binärzahl)
- Ableitungsbäume
- Pumping Lemma, Halteproblem TM → Multiple Choice
- Compilerbau (nur Grob) → LL(1)-Grammatiken, FIRST/FOLLOW
- Algorithmen:
- Potenzmengenkonstruktion
- Baukastenmethode (RE → NEA → DEA → RE)
- Zustandselimination
- Minimierung EA
- Minimierung von kfG, Erzeugung CNF aus kfG
- CYK-Alg. (Wortproblem)
TODO
- Pumping Lemma
- Berechenbarkeit
- Halteproblem
- Compilerbau
- Einführung
- Definition
- Compiler-Phasen
- Frontend
- Backend
- Vergleich zu Interpreter
- Programmtext
- Lexikalische Analyse
- Probleme & heutiger Ansatz
- Syntaxanalyse
- Parser
- Grammatik
- Ableitung
- Eindeutige Grammatiken
- Termbäume
- Recursive Descent Parset
- LL(1)-Grammatiken
- Top-Down Parsing
- Shift-Reduce-Parser
- LR(1)-Grammatiken
- Parsergeneratoren
- Bison
- Fehlererkennung
- Symboltabellen
- Codeoptimierung
- Einführung